
Garrett Bingham
I am a senior research scientist at Google DeepMind, focused on advanced reasoning. I proposed Deep Think, a method which enables Gemini to consider multiple hypotheses in parallel before responding. I co-led development of the AI systems that achieved gold (2025) and silver (2024) medals at the International Mathematical Olympiad. I also contributed to IMO-Bench and HaloQuest: datasets for advancing mathematical and multimodal reasoning in language models.
Prior to joining GDM, I introduced methods for discovering better activation functions and automating weight initialization for neural networks. This work received the SIGEVO Best Dissertation Award Honorable Mention and Neural Networks Best Paper Award.
In the News

Accelerating Mathematical and Scientific Discovery with Gemini Deep Think
February 11, 2026
Google DeepMind
Gemini achieves gold-medal level at the International Collegiate Programming Contest World Finals
September 17, 2025
Google DeepMind


Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad
July 21, 2025
Google DeepMind

Risto Miikkulainen’s Leadership in AI Research and Industry Recognized Globally
December 4, 2024
The University of Texas at Austin

AI achieves silver-medal standard solving International Mathematical Olympiad problems
July 25, 2024
Google DeepMind


TXCS Researchers Design Evolutionary Algorithms for Neural Networks
May 28, 2020
The University of Texas at Austin
Research Publications
Aletheia tackles FirstProof autonomously
Tony Feng, Junehyuk Jung, Sang-hyun Kim, Carlo Pagano, Sergei Gukov, Chiang-Chiang Tsai, David Woodruff, Adel Javanmard, Aryan Mokhtari, Dawsen Hwang, Yuri Chervonyi, Jonathan N. Lee, Garrett Bingham, Trieu H. Trinh, Vahab Mirrokni, Quoc V. Le, Thang Luong
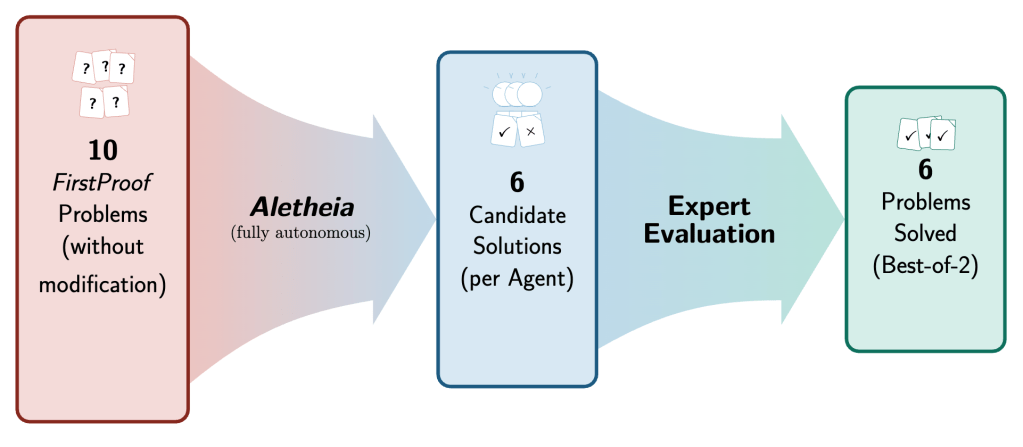
We report the performance of Aletheia (Feng et al., 2026b), a mathematics research agent powered by Gemini 3 Deep Think, on the inaugural FirstProof challenge. Within the allowed timeframe of the challenge, Aletheia autonomously solved 6 problems (2, 5, 7, 8, 9, 10) out of 10 according to majority expert assessments; we note that experts were not unanimous on Problem 8 (only). For full transparency, we explain our interpretation of FirstProof and disclose details about our experiments as well as our evaluation. Raw prompts and outputs are available at https://github.com/google-deepmind/superhuman/tree/main/aletheia.
Towards Autonomous Mathematics Research
Tony Feng, Trieu H. Trinh, Garrett Bingham, Dawsen Hwang, Yuri Chervonyi, Junehyuk Jung, Joonkyung Lee, Carlo Pagano, Sang-hyun Kim, Federico Pasqualotto, Sergei Gukov, Jonathan N. Lee, Junsu Kim, Kaiying Hou, Golnaz Ghiasi, Yi Tay, YaGuang Li, Chenkai Kuang, Yuan Liu, Hanzhao (Maggie) Lin, Evan Zheran Liu, Nigamaa Nayakanti, Xiaomeng Yang, Heng-tze Cheng, Demis Hassabis, Koray Kavukcuoglu, Quoc V. Le, Thang Luong
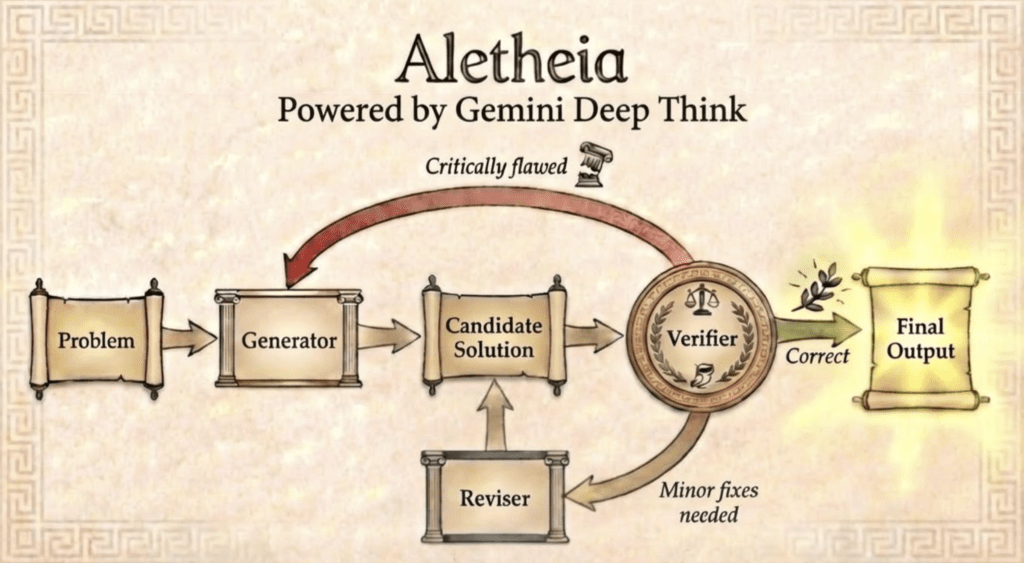
Recent advances in foundational models have yielded reasoning systems capable of achieving a gold-medal standard at the International Mathematical Olympiad. The transition from competition-level problem-solving to professional research, however, requires navigating vast literature and constructing long-horizon proofs. In this work, we introduce Aletheia, a math research agent that iteratively generates, verifies, and revises solutions end-to-end in natural language. Specifically, Aletheia is powered by an advanced version of Gemini Deep Think for challenging reasoning problems, a novel inference-time scaling law that extends beyond Olympiad-level problems, and intensive tool use to navigate the complexities of mathematical research. We demonstrate the capability of Aletheia from Olympiad problems to PhD-level exercises and most notably, through several distinct milestones in AI-assisted mathematics research: (a) a research paper (Feng26) generated by AI without any human intervention in calculating certain structure constants in arithmetic geometry called eigenweights; (b) a research paper (LeeSeo26) demonstrating human-AI collaboration in proving bounds on systems of interacting particles called independent sets; and (c) an extensive semi-autonomous evaluation (Feng et al., 2026a) of 700 open problems on Bloom’s Erdos Conjectures database, including autonomous solutions to four open questions. In order to help the public better understand the developments pertaining to AI and mathematics, we suggest codifying standard levels quantifying autonomy and novelty of AI-assisted results. We conclude with reflections on human-AI collaboration in mathematics.
Semi-Autonomous Mathematics Discovery with Gemini: A Case Study on the Erdős Problems
Tony Feng, Trieu Trinh, Garrett Bingham, Jiwon Kang, Shengtong Zhang, Sang-hyun Kim, Kevin Barreto, Carl Schildkraut, Junehyuk Jung, Jaehyeon Seo, Carlo Pagano, Yuri Chervonyi, Dawsen Hwang, Kaiying Hou, Sergei Gukov, Cheng-Chiang Tsai, Hyunwoo Choi, Youngbeom Jin, Wei-Yuan Li, Hao-An Wu, Ruey-An Shiu, Yu-Sheng Shih, Quoc V. Le, Thang Luong
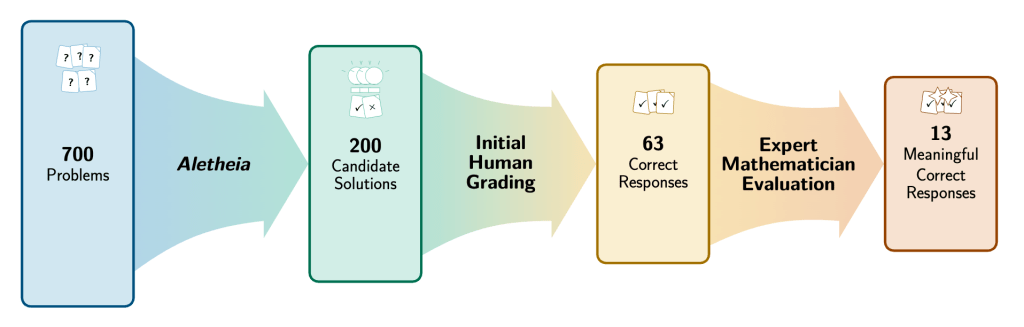
We present a case study in semi-autonomous mathematics discovery, using Gemini to systematically evaluate 700 conjectures labeled ‘Open’ in Bloom’s Erdős Problems database. We employ a hybrid methodology: AI-driven natural language verification to narrow the search space, followed by human expert evaluation to gauge correctness and novelty. We address 13 problems that were marked ‘Open’ in the database: 5 through seemingly novel autonomous solutions, and 8 through identification of previous solutions in the existing literature. Our findings suggest that the ‘Open’ status of the problems was through obscurity rather than difficulty. We also identify and discuss issues arising in applying AI to math conjectures at scale, highlighting the difficulty of literature identification and the risk of ”subconscious plagiarism” by AI. We reflect on the takeaways from AI-assisted efforts on the Erdős Problems.
Towards Robust Mathematical Reasoning
Thang Luong , Dawsen Hwang, Hoang H. Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, Alex Zhai, Clara Huiyi Hu, Henryk Michalewski, Jimin Kim, Jeonghyun Ahn, Junhwi Bae, Xingyou Song, Trieu H. Trinh, Quoc V. Le, and Junehyuk Jung
EMNLP 2025
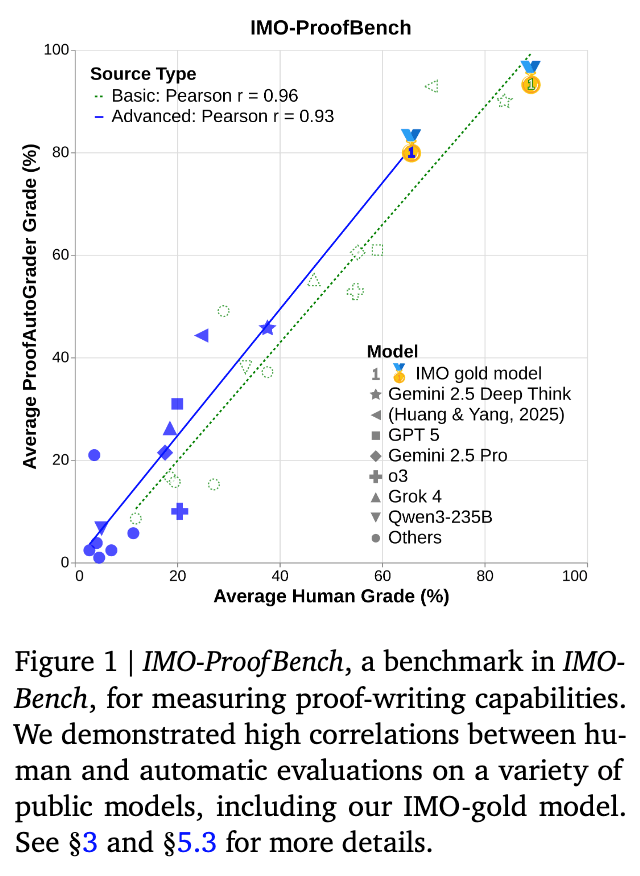
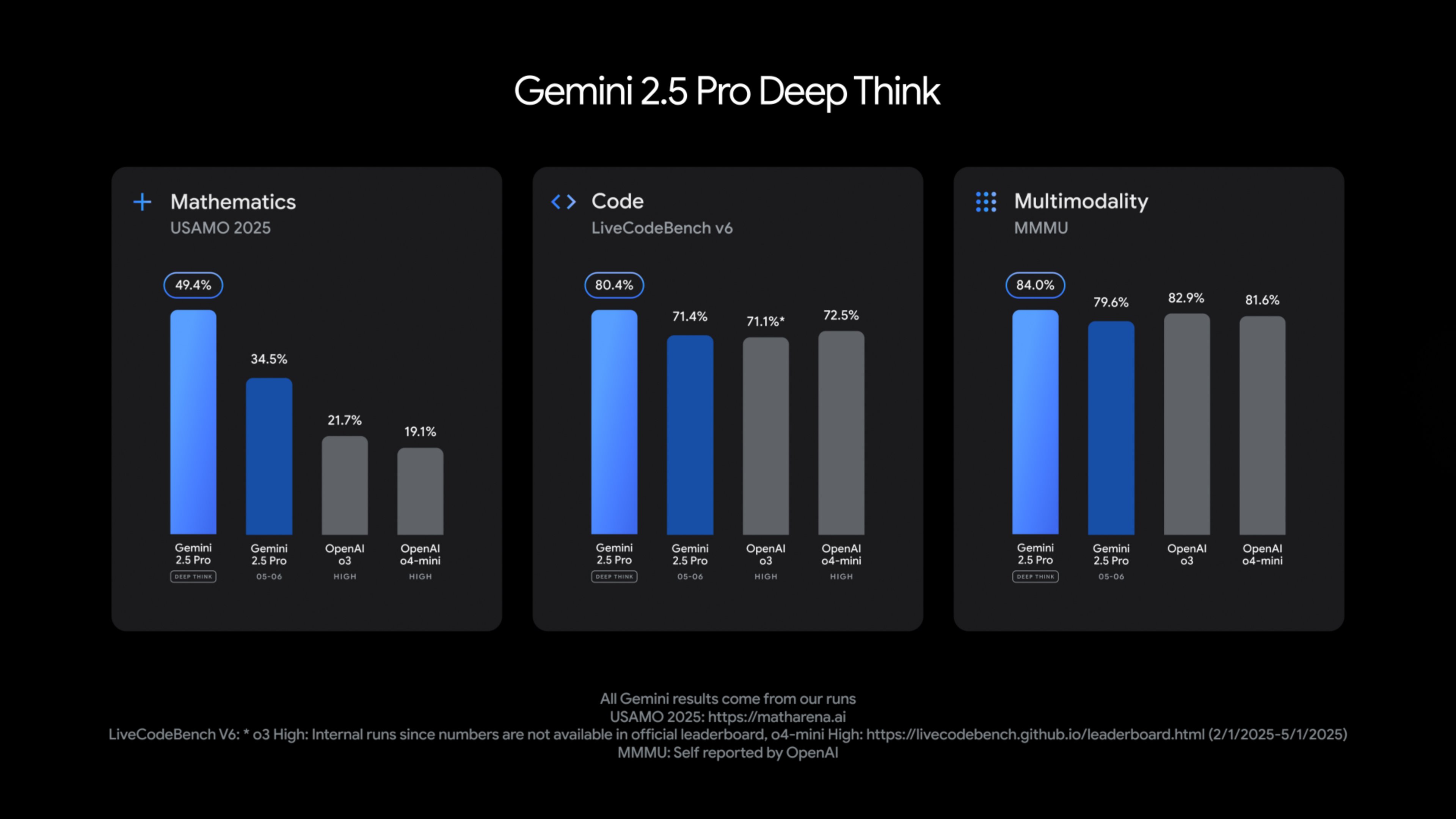
Finding the right north-star metrics is highly critical for advancing the mathematical reasoning capabilities of foundation models, especially given that existing evaluations are either too easy or only focus on getting correct short answers. To address these issues, we present IMO-Bench, a suite of advanced reasoning benchmarks, vetted by a panel of top specialists and that specifically targets the level of the International Mathematical Olympiad (IMO), the most prestigious venue for young mathematicians. IMO-AnswerBench first tests models on 400 diverse Olympiad problems with verifiable short answers. IMO-Proof Bench is the next level evaluation for proof-writing capabilities, which includes both basic and advanced IMO level problems as well as detailed grading guidelines to facilitate automatic grading. These benchmarks played a crucial role in our historic achievement of the gold-level performance at IMO 2025 with Gemini Deep Think (Luong and Lockhart, 2025). Our model achieved 80.0% on IMO-AnswerBench and 65.7% on the advanced IMO-Proof Bench, surpassing the best non-Gemini models by large margins of 6.9% and 42.4% respectively. We also showed that autograders built with Gemini reasoning correlate well with human evaluations and construct IMO-GradingBench, with 1000 human gradings on proofs, to enable further progress in automatic evaluation of long-form answers. We hope that IMO-Bench will help the community towards advancing robust mathematical reasoning and release it at https://imobench.github.io.
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities
Gemini Team, Google
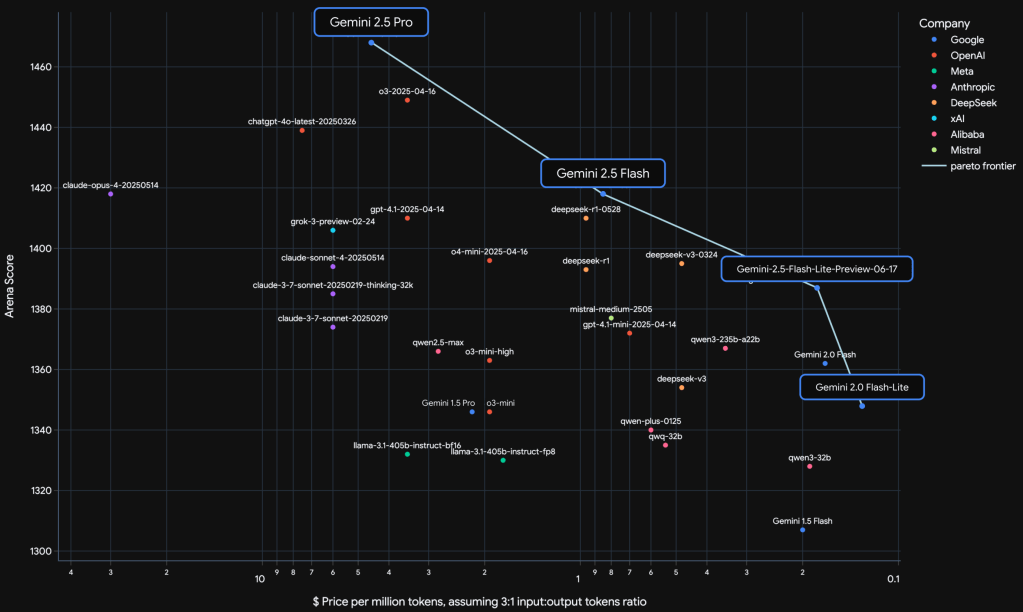
In this report, we introduce the Gemini 2.X model family: Gemini 2.5 Pro and Gemini 2.5 Flash, as well as our earlier Gemini 2.0 Flash and Flash-Lite models. Gemini 2.5 Pro is our most capable model yet, achieving SoTA performance on frontier coding and reasoning benchmarks. In addition to its incredible coding and reasoning skills, Gemini 2.5 Pro is a thinking model that excels at multimodal understanding and it is now able to process up to 3 hours of video content. Its unique combination of long context, multimodal and reasoning capabilities can be combined to unlock new agentic workflows. Gemini 2.5 Flash provides excellent reasoning abilities at a fraction of the compute and latency requirements and Gemini 2.0 Flash and Flash-Lite provide high performance at low latency and cost. Taken together, the Gemini 2.X model generation spans the full Pareto frontier of model capability vs cost, allowing users to explore the boundaries of what is possible with complex agentic problem solving.
HaloQuest: A Visual Hallucination Dataset for Advancing Multimodal Reasoning
Zhecan Wang*, Garrett Bingham*, Adams Wei Yu, Quoc V. Le, Thang Luong, and Golnaz Ghiasi
ECCV 2024


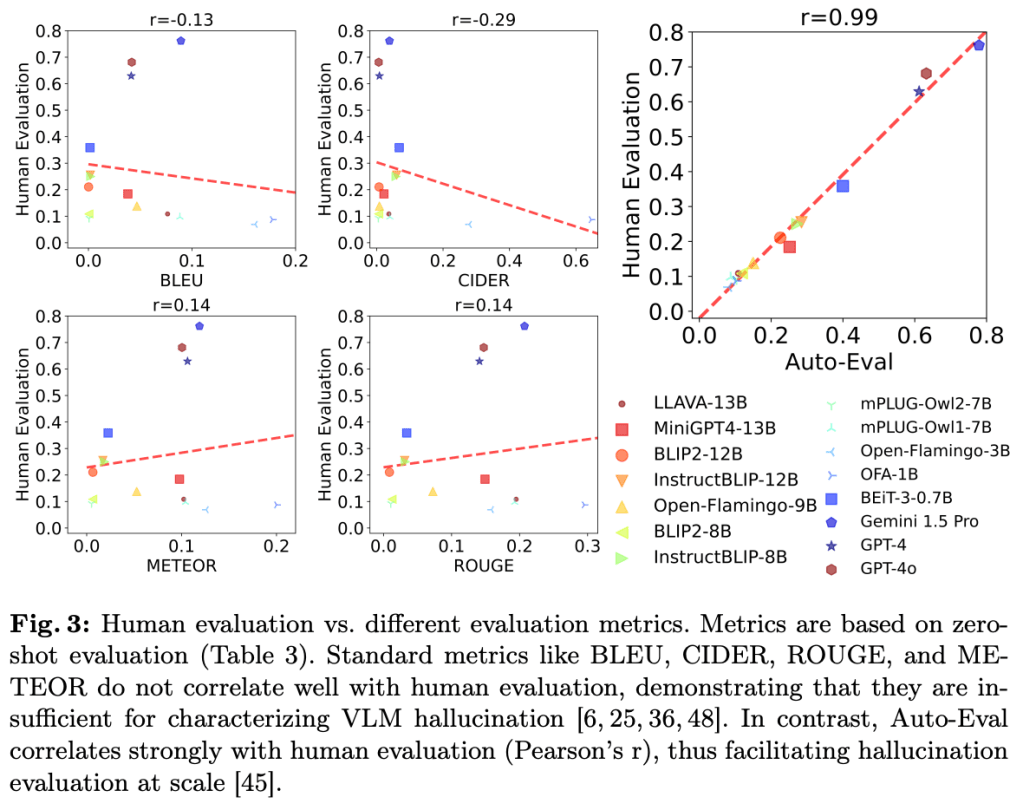
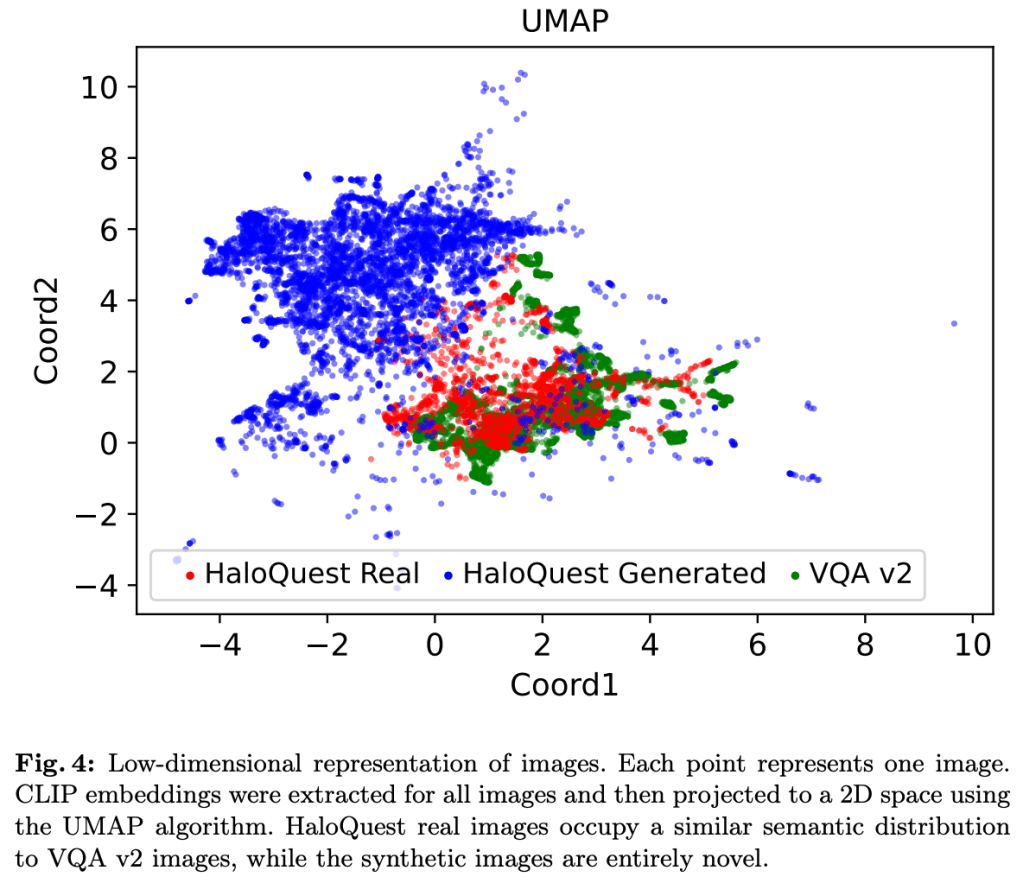


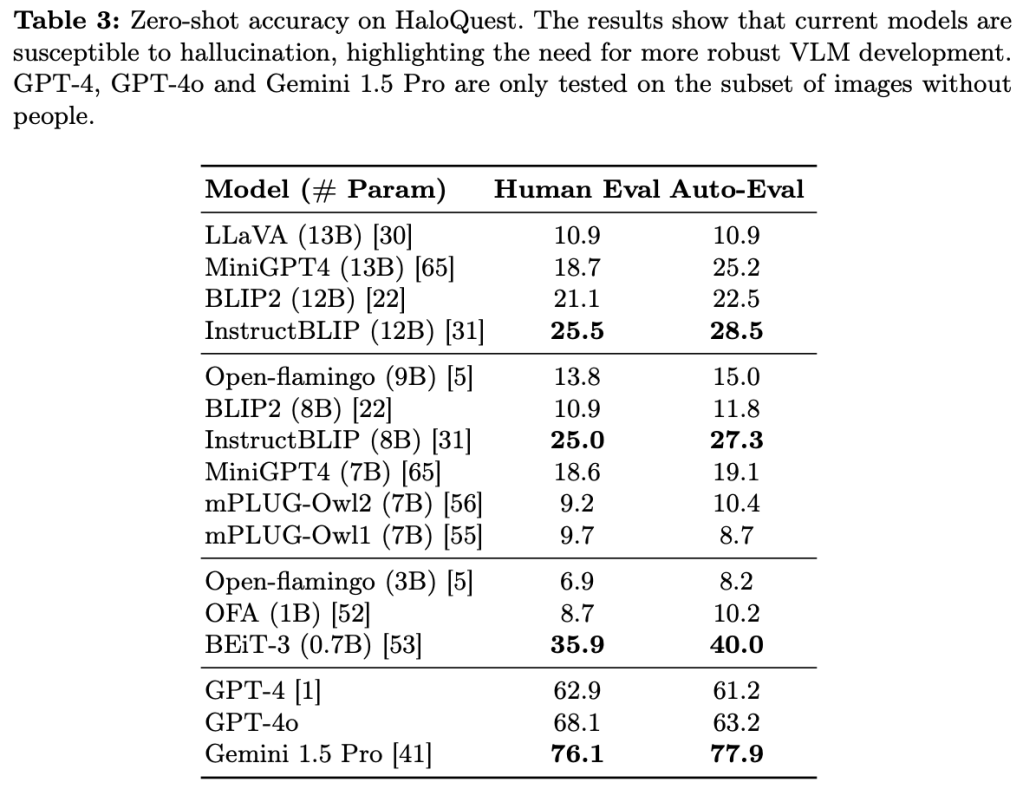

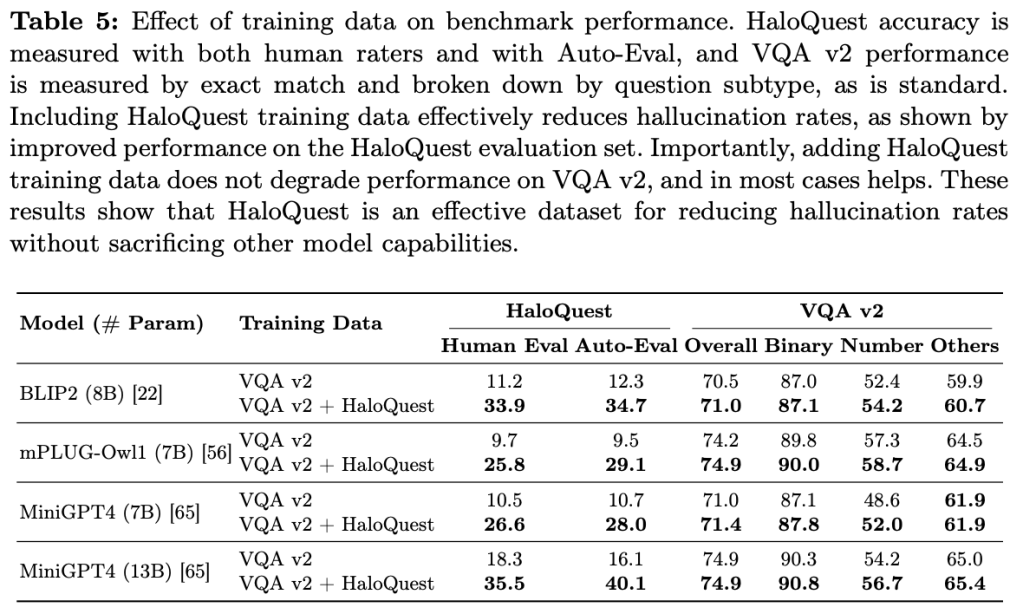

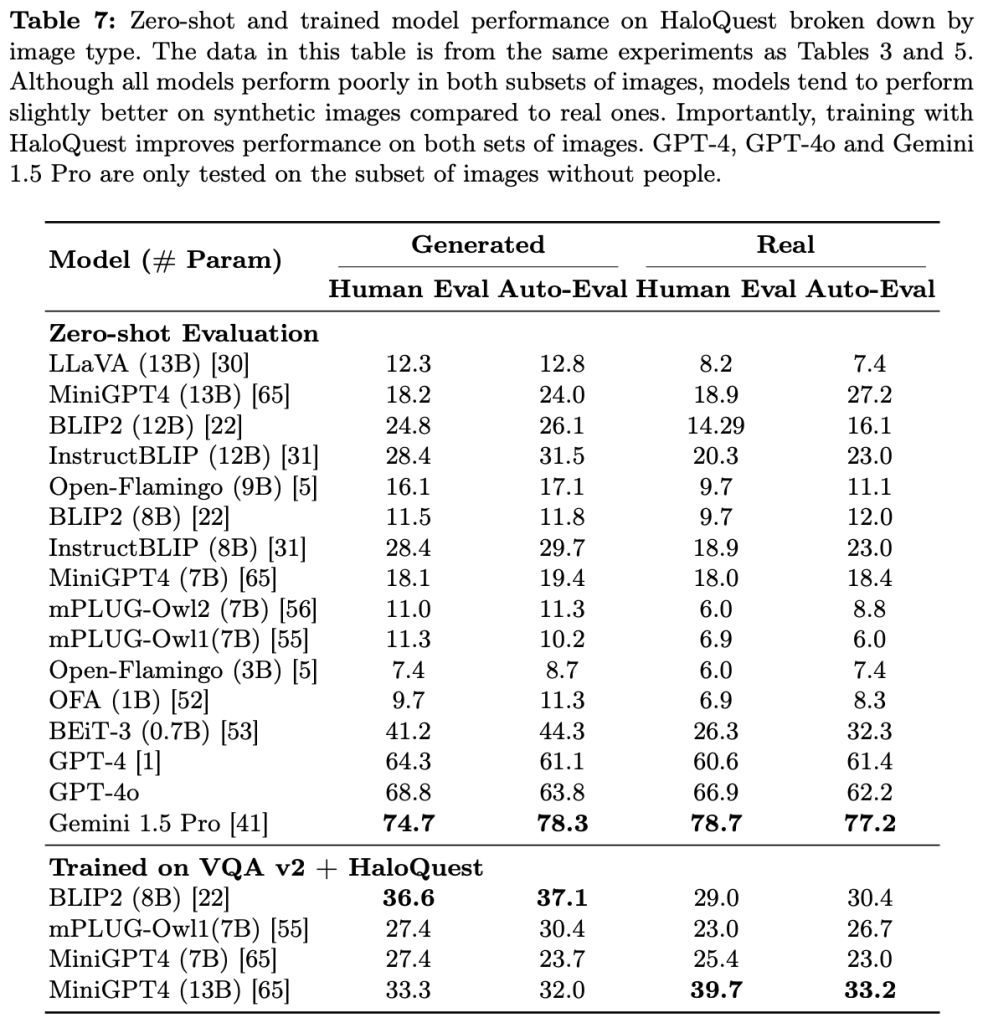
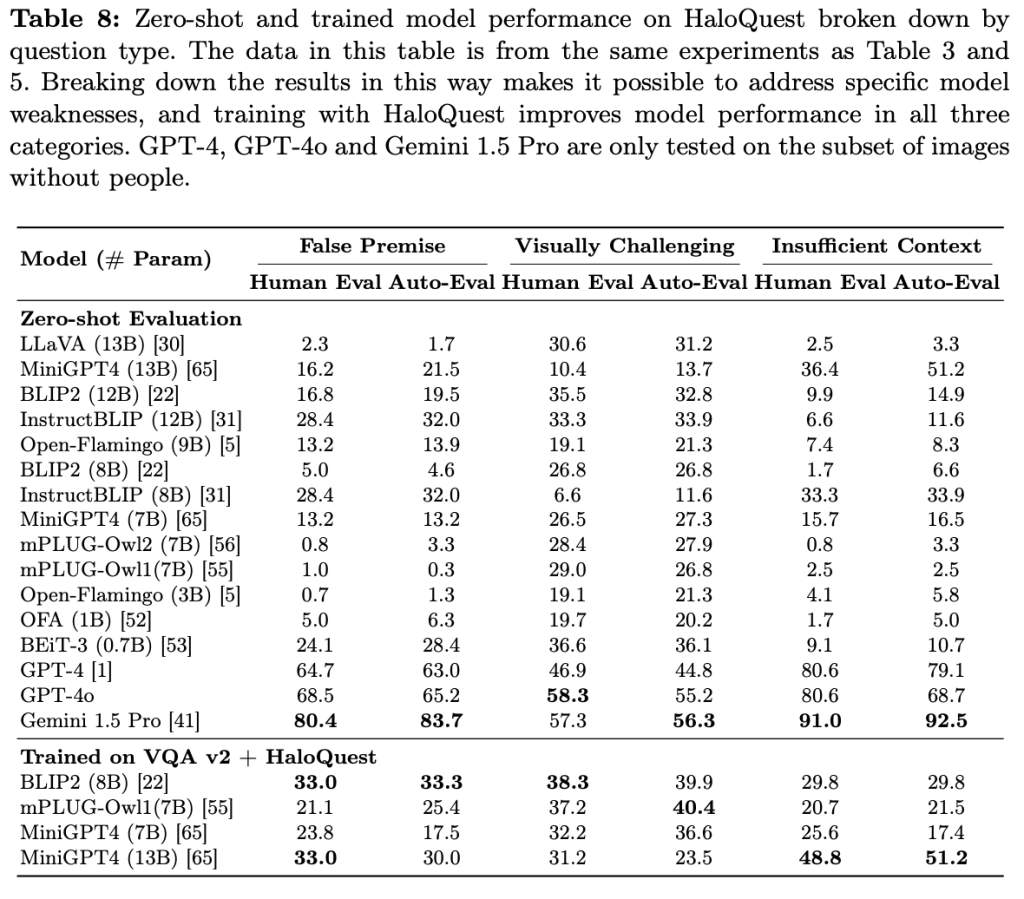
Hallucination has been a major problem for large language models and remains a critical challenge when it comes to multimodality in which vision-language models (VLMs) have to deal with not just textual but also visual inputs. Despite rapid progress in VLMs, resources for evaluating and addressing multimodal hallucination are limited and mostly focused on evaluation. This work introduces HaloQuest, a novel visual question answering dataset that captures various aspects of multimodal hallucination such as false premises, insufficient contexts, and visual challenges. A novel idea from HaloQuest is to leverage synthetic images, apart from real ones, to enable dataset creation at scale. With over 7.7K examples spanning across a wide variety of categories, HaloQuest was designed to be both a challenging benchmark for VLMs and a fine-tuning dataset for advancing multimodal reasoning. Our experiments reveal that current models struggle with HaloQuest, with all open-source VLMs achieving below 36% accuracy. On the other hand, fine-tuning on HaloQuest significantly reduces hallucination rates while preserving performance on standard reasoning tasks. Our results discover that benchmarking with generated images is highly correlated (r=0.97) with real images. Last but not least, we propose a novel Auto-Eval mechanism that is highly correlated with human raters (r=0.99) for evaluating VLMs. In sum, this work makes concrete strides towards understanding, evaluating, and mitigating hallucination in VLMs, serving as an important step towards more reliable multimodal AI systems in the future.
Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context
Gemini Team, Google
In this report, we introduce the Gemini 1.5 family of models, representing the next generation of highly compute-efficient multimodal models capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. The family includes two new models: (1) an updated Gemini 1.5 Pro, which exceeds the February version on the great majority of capabilities and benchmarks; (2) Gemini 1.5 Flash, a more lightweight variant designed for efficiency with minimal regression in quality. Gemini 1.5 models achieve near-perfect recall on long-context retrieval tasks across modalities, improve the state-of-the-art in long-document QA, long-video QA and long-context ASR, and match or surpass Gemini 1.0 Ultra’s state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5’s long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 3.0 (200k) and GPT-4 Turbo (128k). Finally, we highlight real-world use cases, such as Gemini 1.5 collaborating with professionals on completing their tasks achieving 26 to 75% time savings across 10 different job categories, as well as surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Optimizing Neural Networks through Activation Function Discovery and Automatic Weight Initialization
Garrett Bingham
PhD Dissertation

Automated machine learning (AutoML) methods improve upon existing models by optimizing various aspects of their design. While present methods focus on hyperparameters and neural network topologies, other aspects of neural network design can be optimized as well. To further the state of the art in AutoML, this dissertation introduces techniques for discovering more powerful activation functions and establishing more robust weight initialization for neural networks. These contributions improve performance, but also provide new perspectives on neural network optimization. First, the dissertation demonstrates that discovering solutions specialized to specific architectures and tasks gives better performance than reusing general approaches. Second, it shows that jointly optimizing different components of neural networks is synergistic, and results in better performance than optimizing individual components alone. Third, it demonstrates that learned representations are easier to optimize than hard-coded ones, creating further opportunities for AutoML. The dissertation thus makes concrete progress towards fully automatic machine learning in the future.
Efficient Activation Function Optimization through Surrogate Modeling
Garrett Bingham and Risto Miikkulainen
NeurIPS 2023

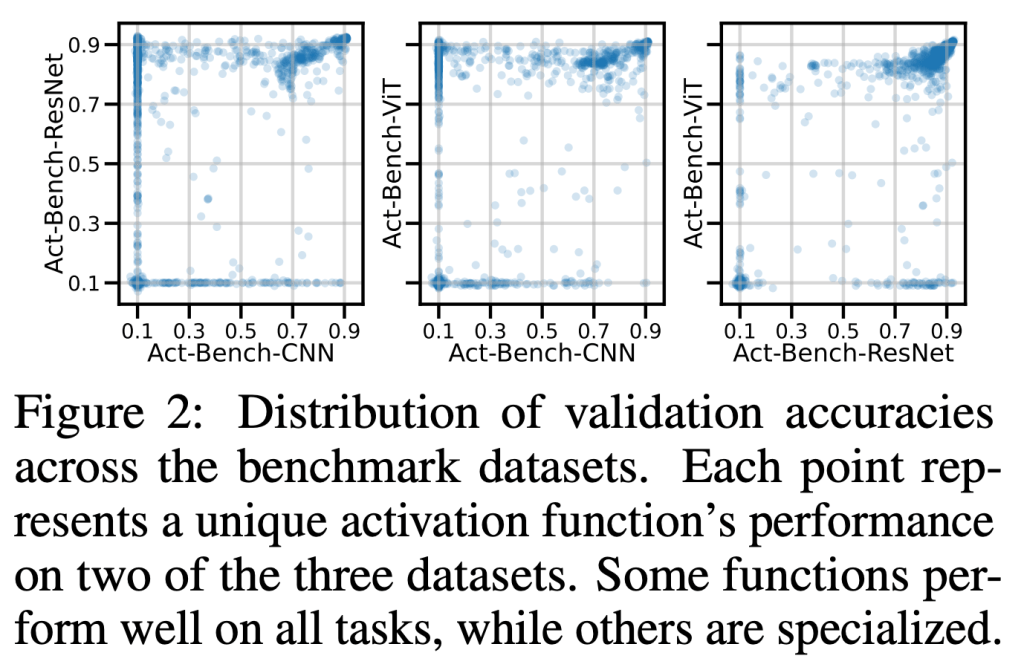



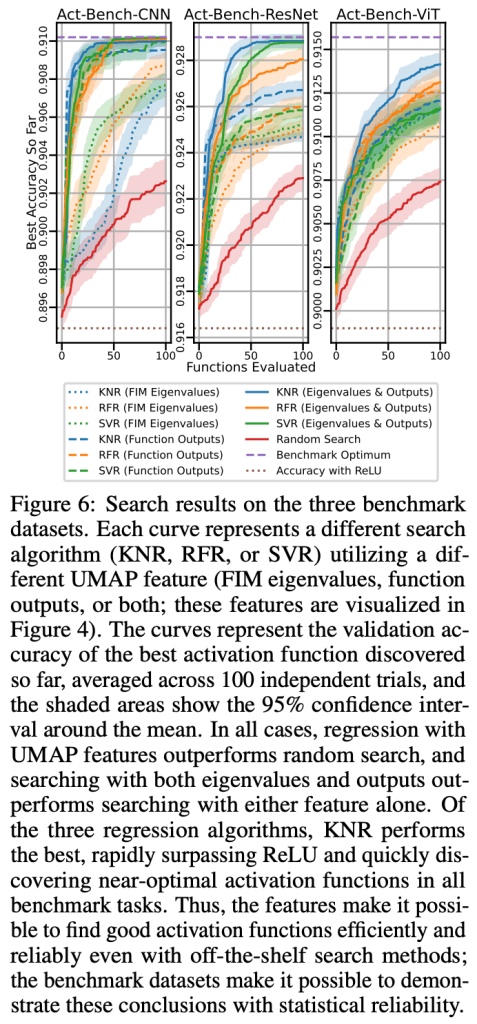
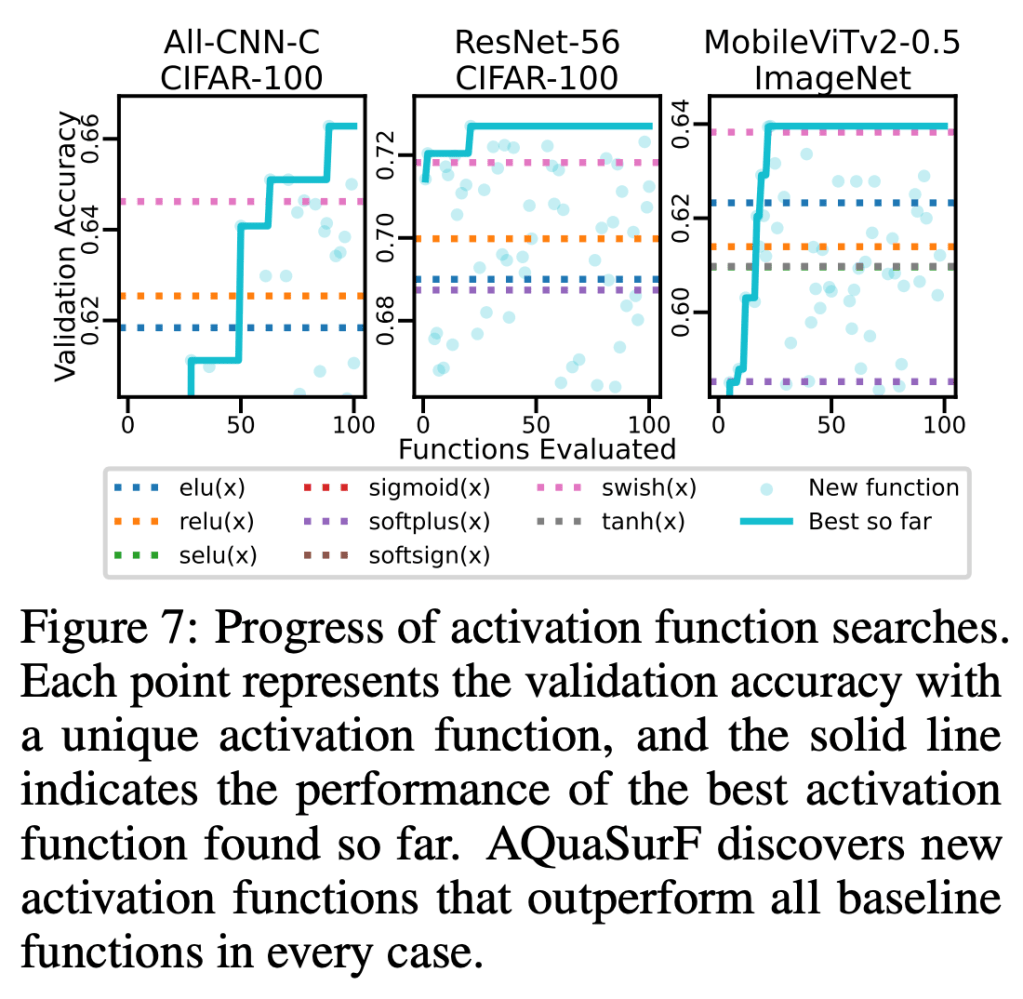

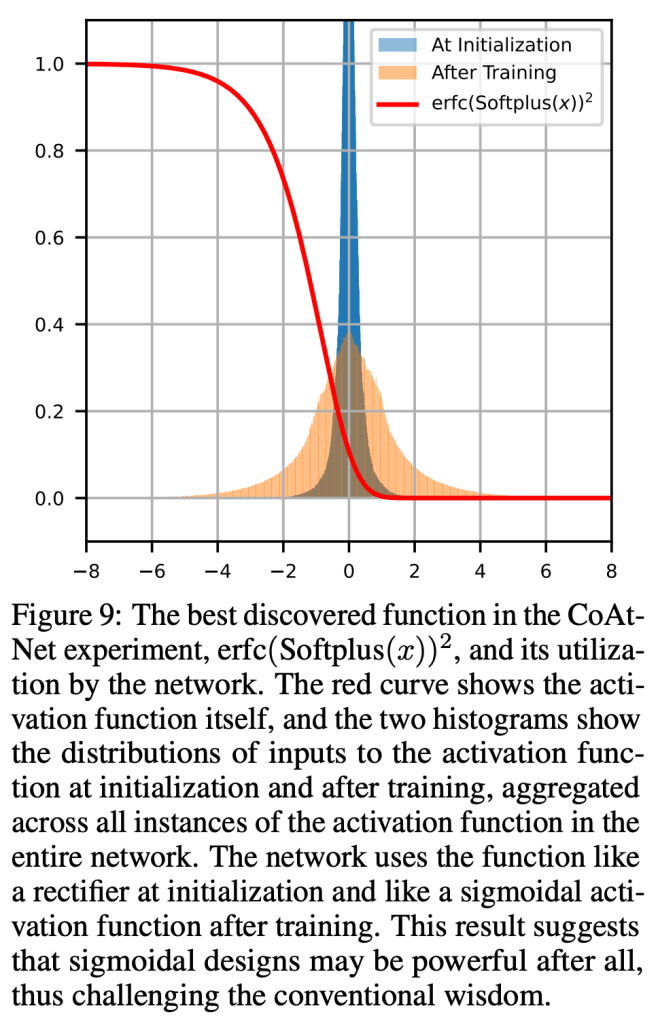




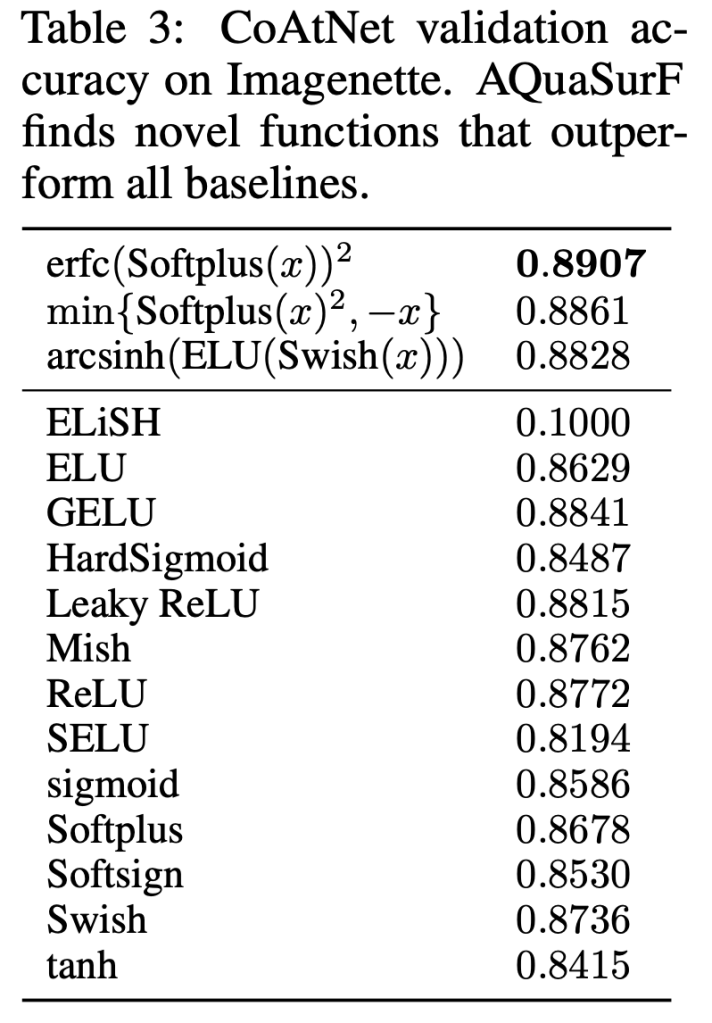
Carefully designed activation functions can improve the performance of neural networks in many machine learning tasks. However, it is difficult for humans to construct optimal activation functions, and current activation function search algorithms are prohibitively expensive. This paper aims to improve the state of the art through three steps: First, the benchmark datasets Act-Bench-CNN, Act-Bench-ResNet, and Act-Bench-ViT were created by training convolutional, residual, and vision transformer architectures from scratch with 2,913 systematically generated activation functions. Second, a characterization of the benchmark space was developed, leading to a new surrogate-based method for optimization. More specifically, the spectrum of the Fisher information matrix associated with the model’s predictive distribution at initialization and the activation function’s output distribution were found to be highly predictive of performance. Third, the surrogate was used to discover improved activation functions in several real-world tasks, with a surprising finding: a sigmoidal design that outperformed all other activation functions was discovered, challenging the status quo of always using rectifier nonlinearities in deep learning. Each of these steps is a contribution in its own right; together they serve as a practical and theoretical foundation for further research on activation function optimization.
AutoInit: Analytic Signal-Preserving Weight Initialization for Neural Networks
Garrett Bingham and Risto Miikkulainen
AAAI 2023
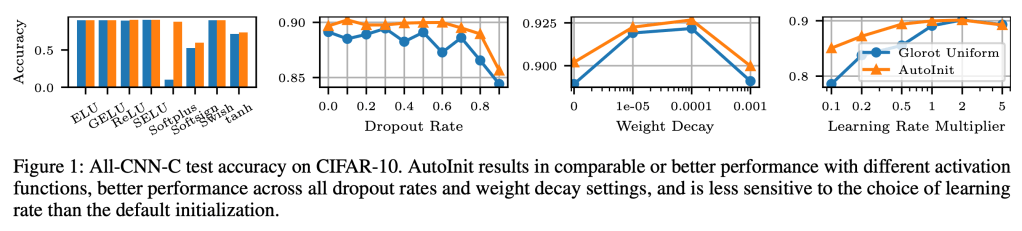
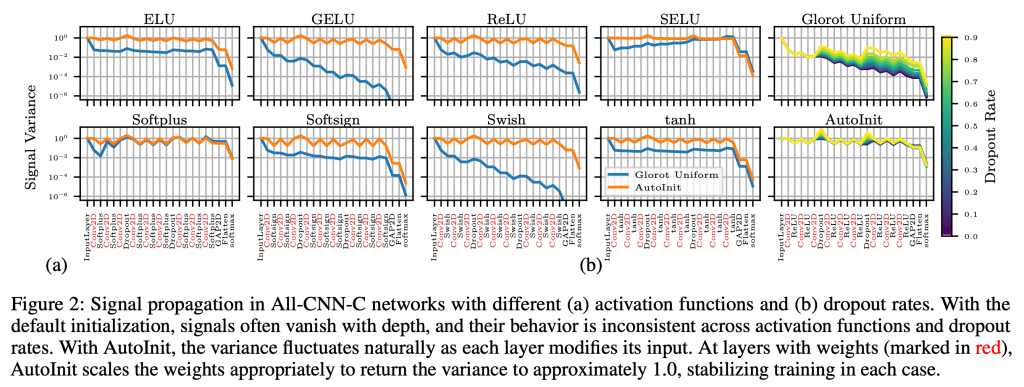
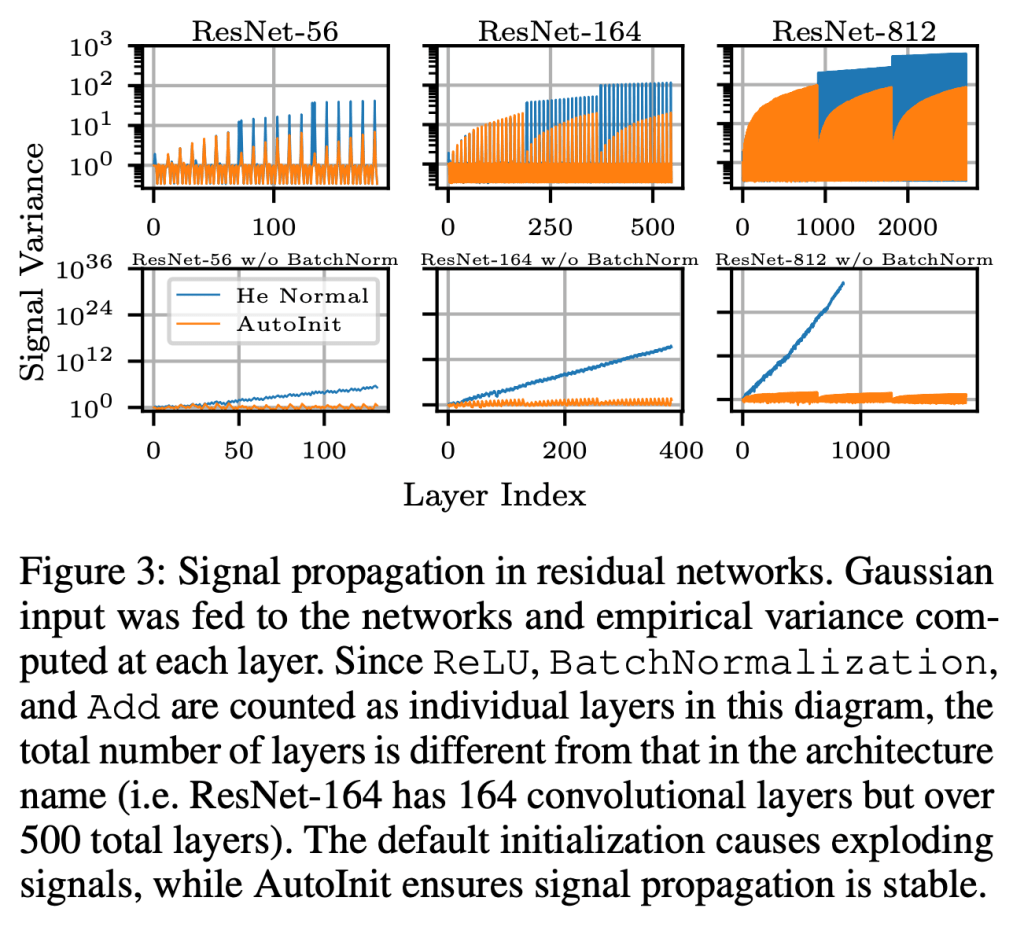
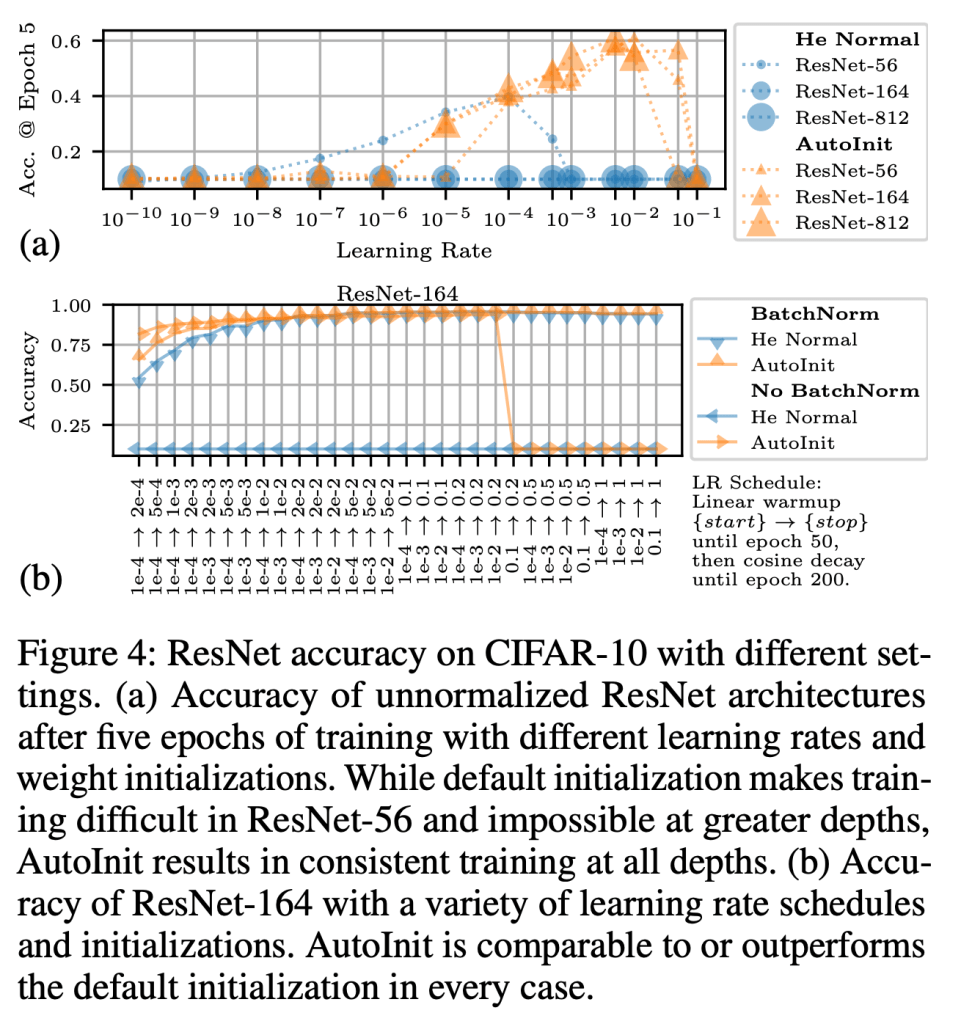
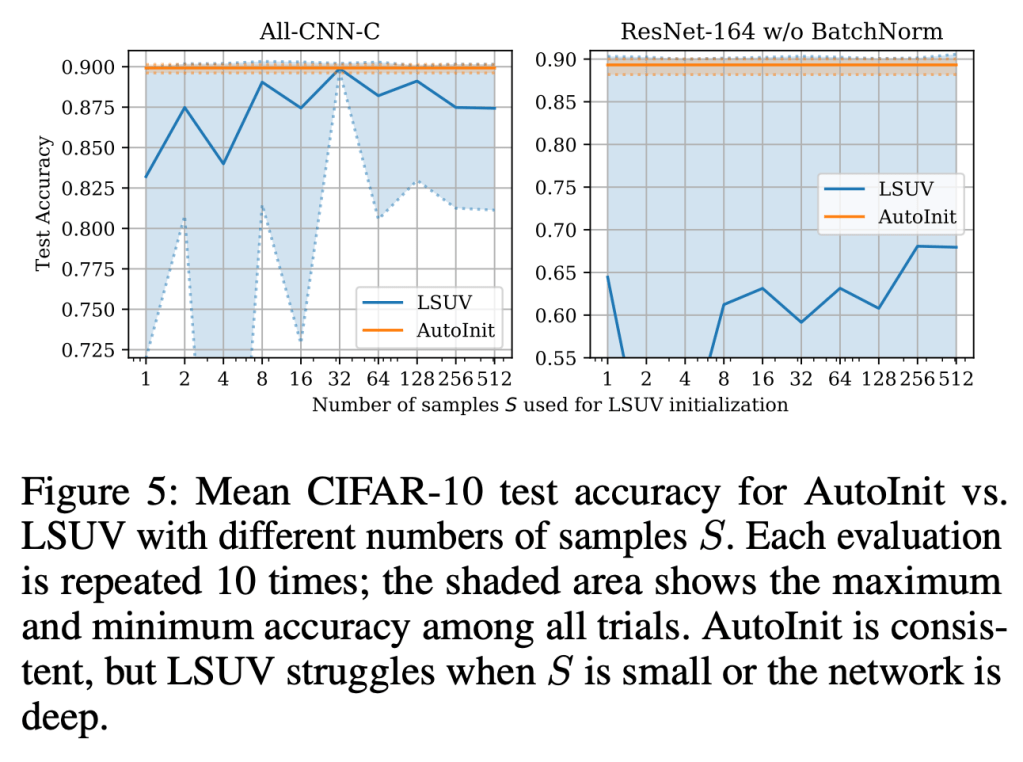
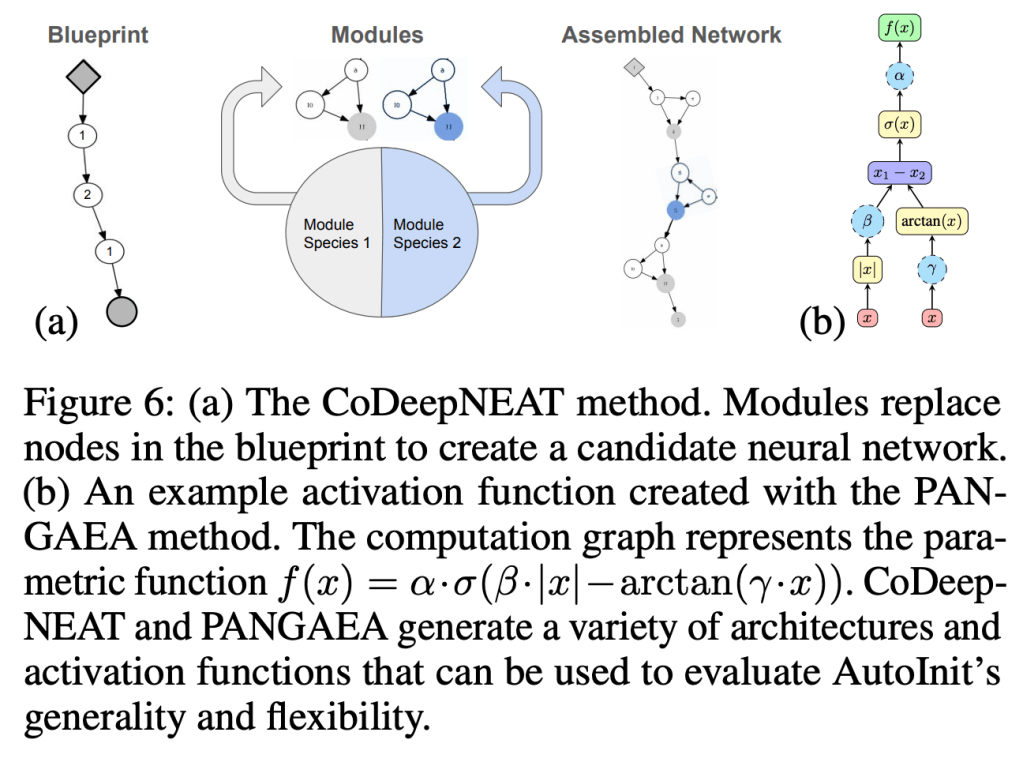
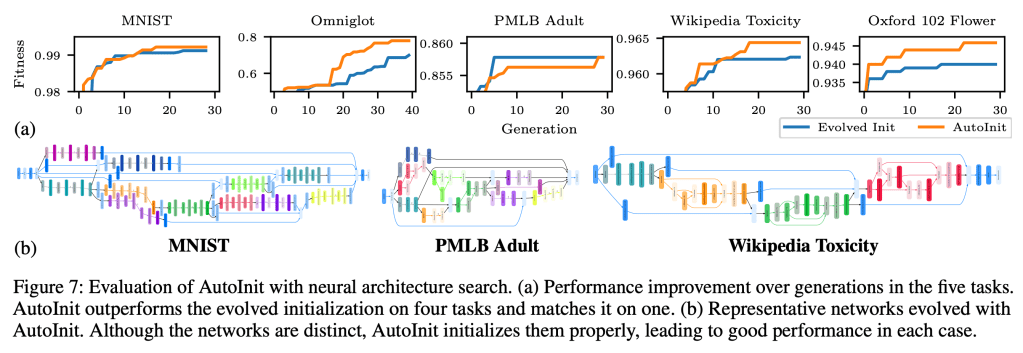
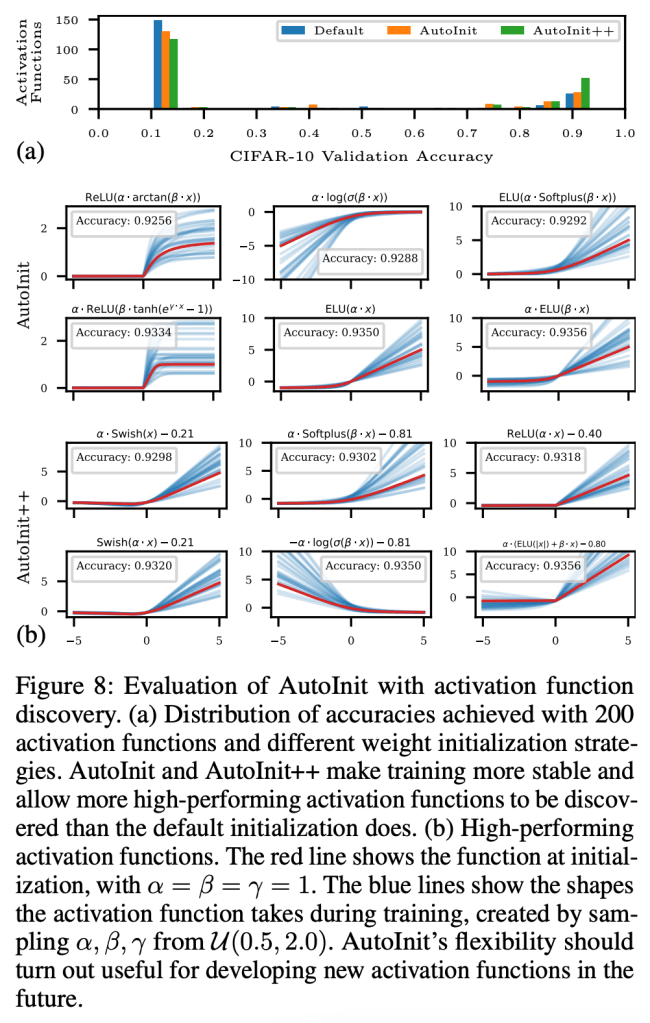

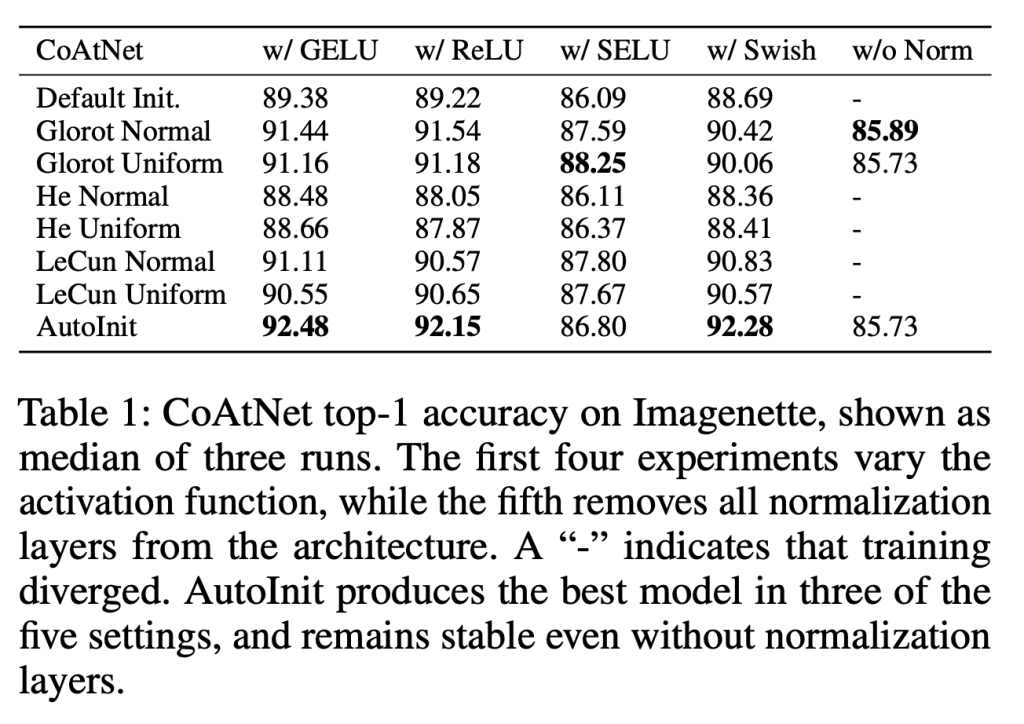

Neural networks require careful weight initialization to prevent signals from exploding or vanishing. Existing initialization schemes solve this problem in specific cases by assuming that the network has a certain activation function or topology. It is difficult to derive such weight initialization strategies, and modern architectures therefore often use these same initialization schemes even though their assumptions do not hold. This paper introduces AutoInit, a weight initialization algorithm that automatically adapts to different neural network architectures. By analytically tracking the mean and variance of signals as they propagate through the network, AutoInit appropriately scales the weights at each layer to avoid exploding or vanishing signals. Experiments demonstrate that AutoInit improves performance of convolutional, residual, and transformer networks across a range of activation function, dropout, weight decay, learning rate, and normalizer settings, and does so more reliably than data-dependent initialization methods. This flexibility allows AutoInit to initialize models for everything from small tabular tasks to large datasets such as ImageNet. Such generality turns out particularly useful in neural architecture search and in activation function discovery. In these settings, AutoInit initializes each candidate appropriately, making performance evaluations more accurate. AutoInit thus serves as an automatic configuration tool that makes design of new neural network architectures more robust. The AutoInit package provides a wrapper around TensorFlow models and is available at https://github.com/cognizant-ai-labs/autoinit.
Discovering Parametric Activation Functions
Garrett Bingham and Risto Miikkulainen
Neural Networks
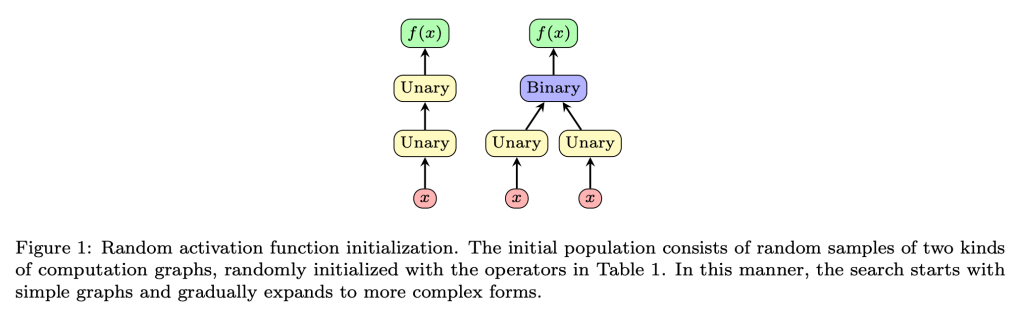
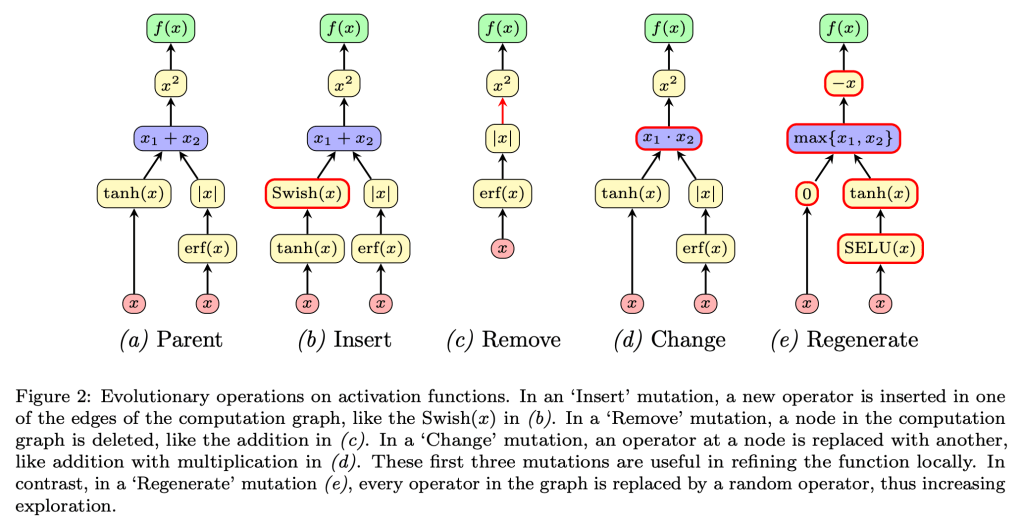
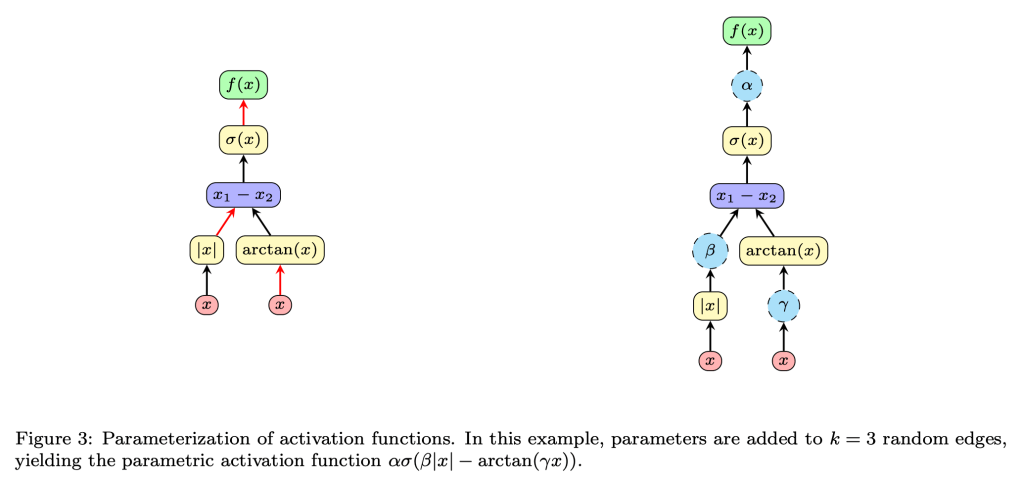
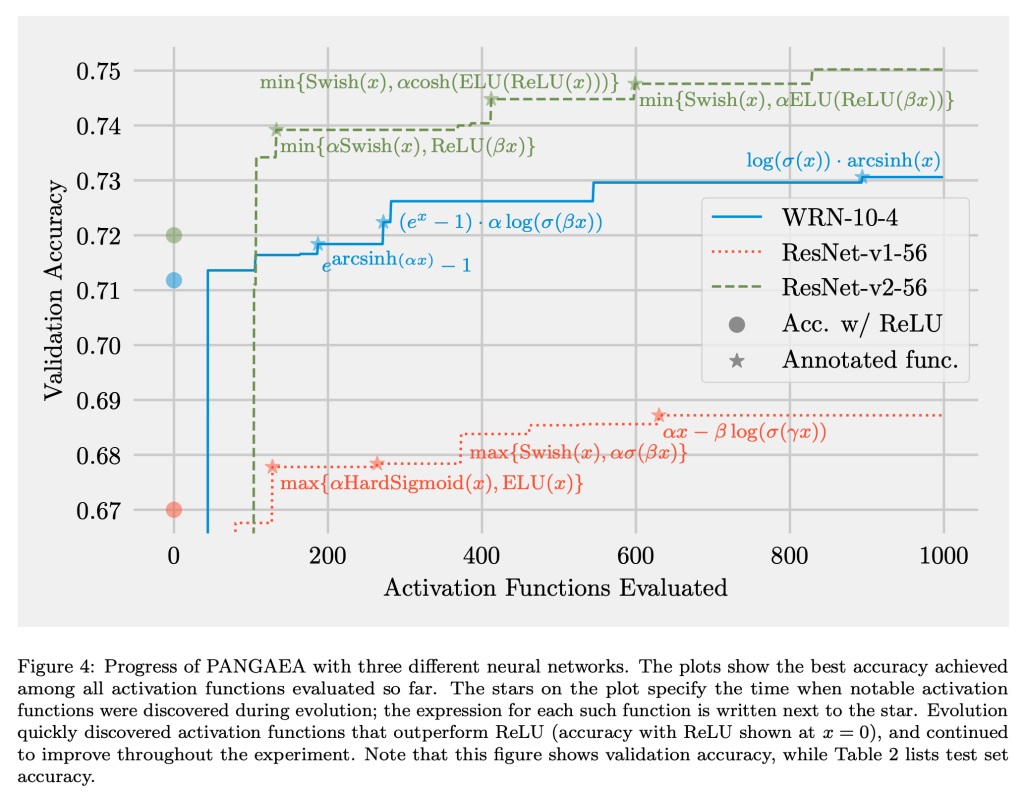
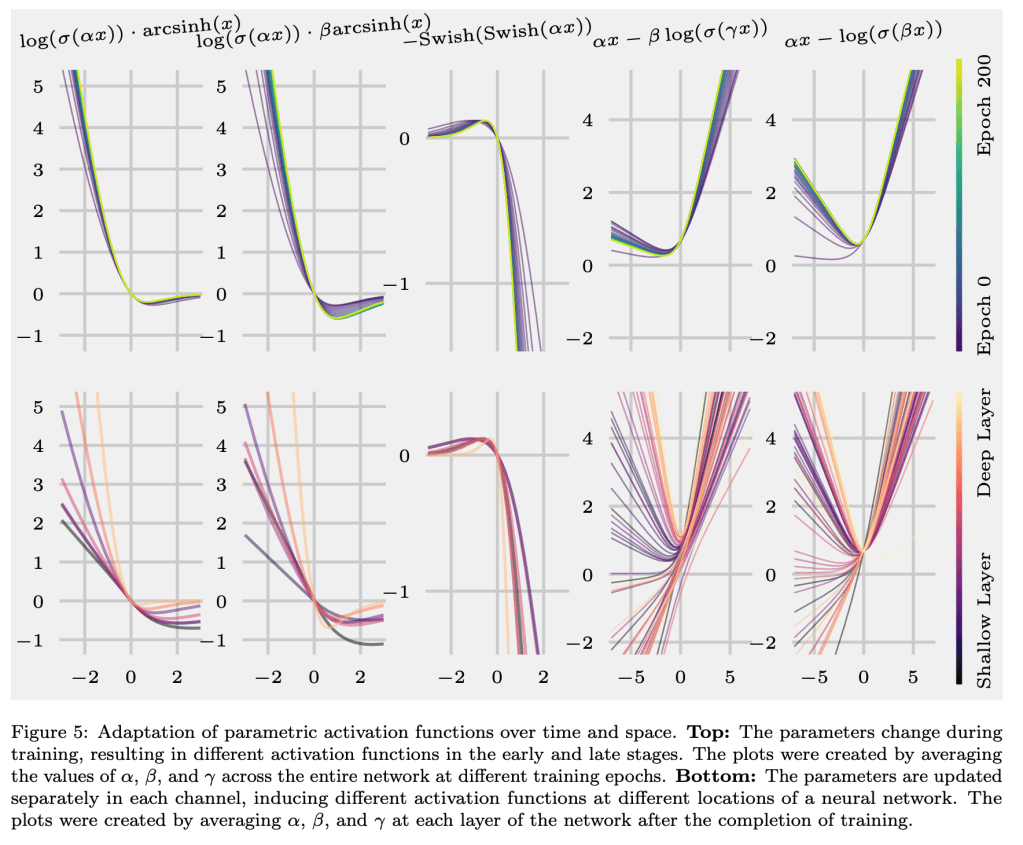
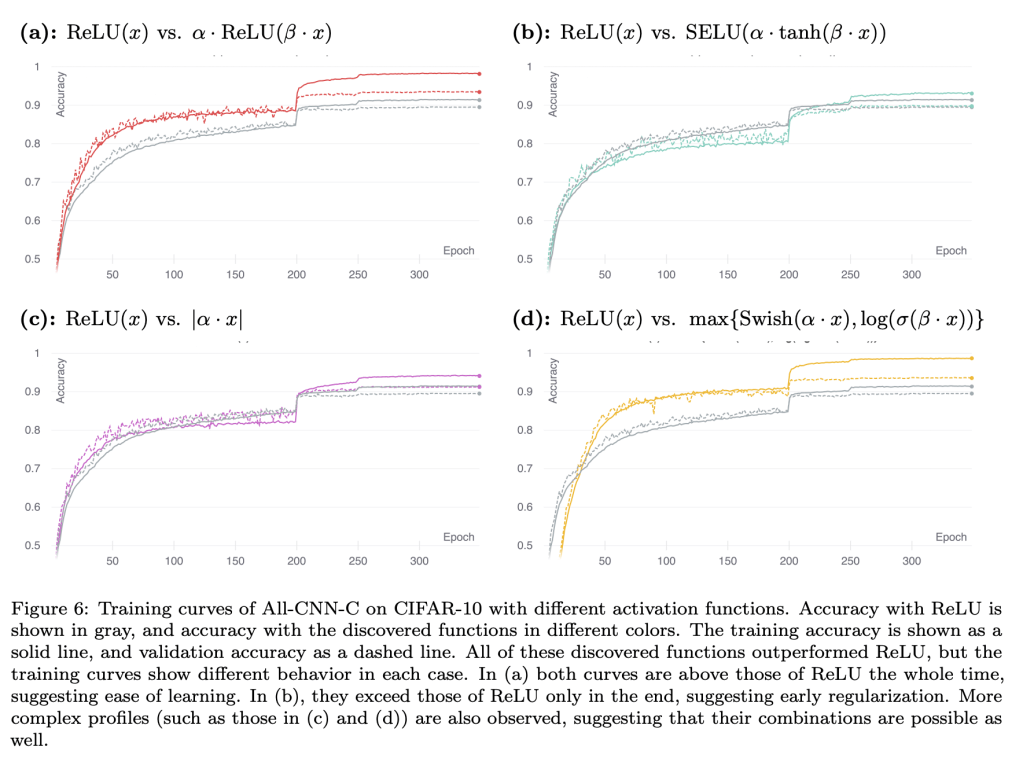

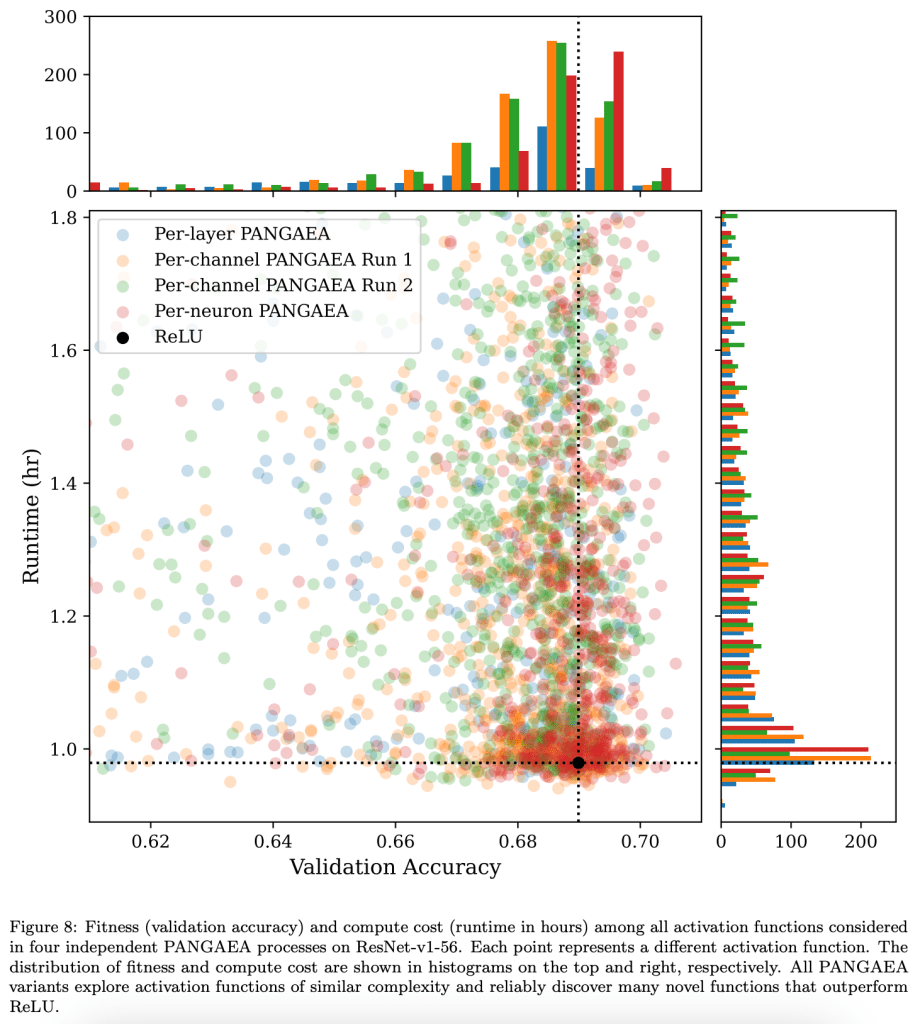
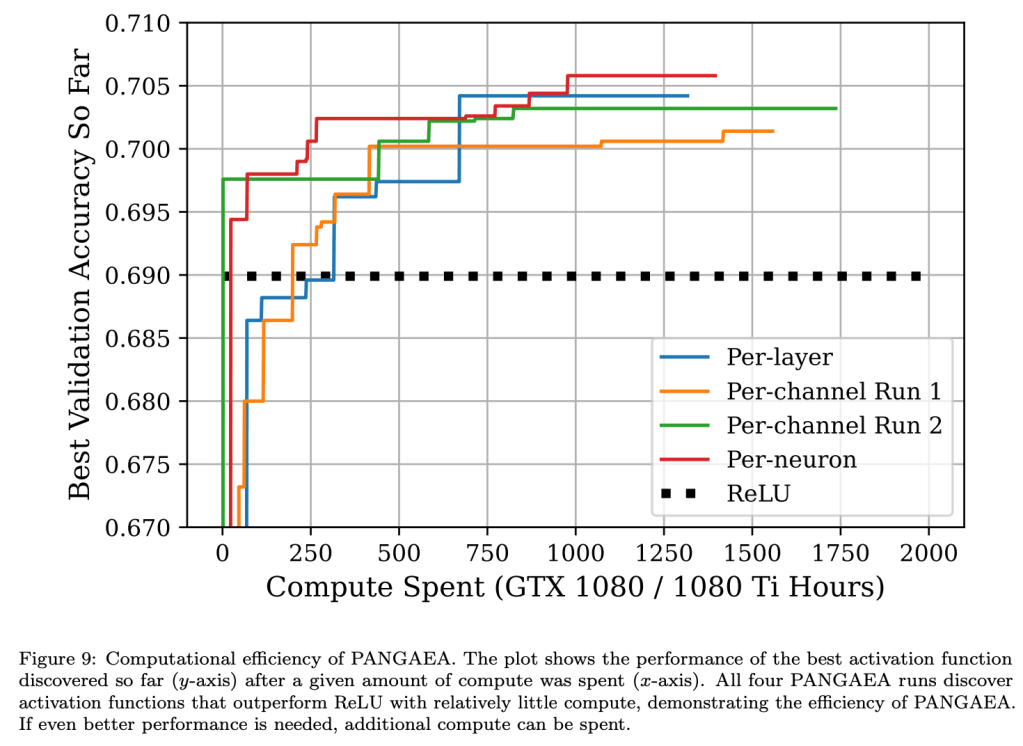

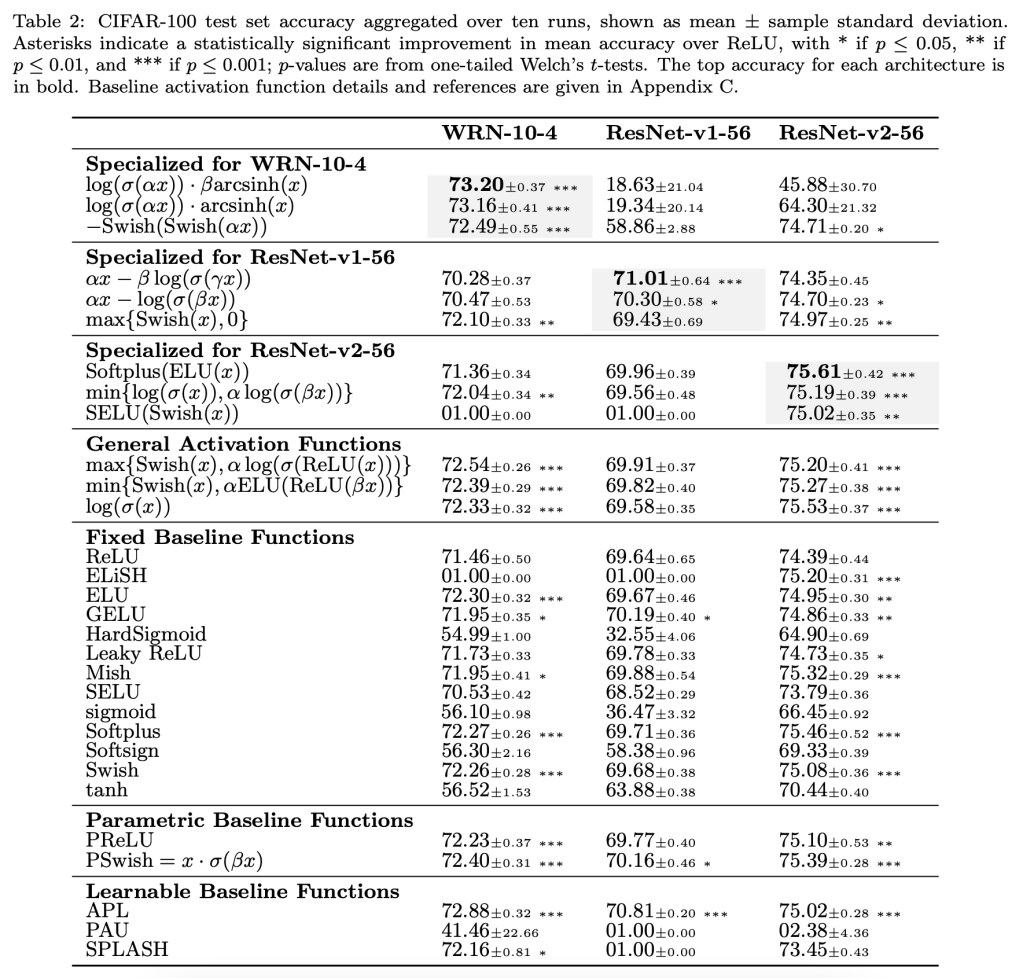
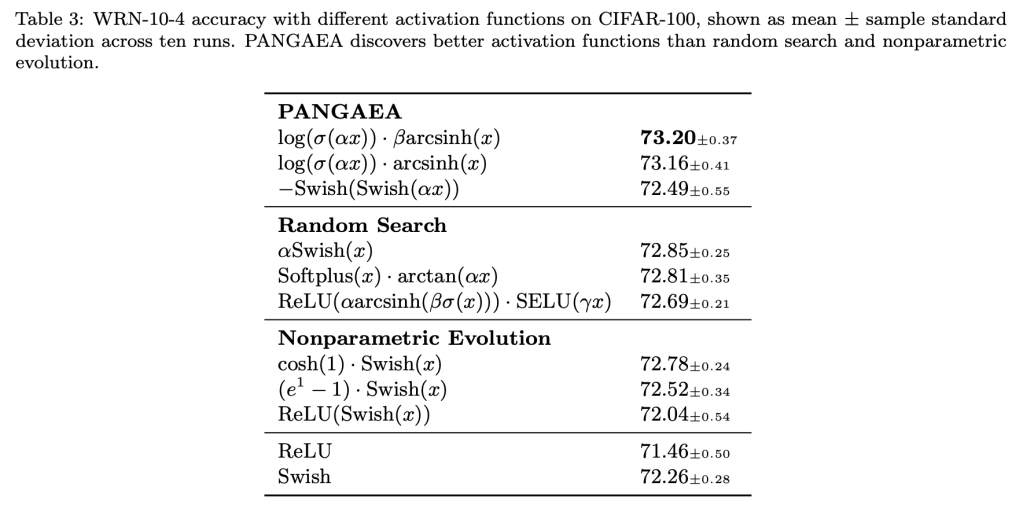





Recent studies have shown that the choice of activation function can significantly affect the performance of deep learning networks. However, the benefits of novel activation functions have been inconsistent and task dependent, and therefore the rectified linear unit (ReLU) is still the most commonly used. This paper proposes a technique for customizing activation functions automatically, resulting in reliable improvements in performance. Evolutionary search is used to discover the general form of the function, and gradient descent to optimize its parameters for different parts of the network and over the learning process. Experiments with four different neural network architectures on the CIFAR-10 and CIFAR-100 image classification datasets show that this approach is effective. It discovers both general activation functions and specialized functions for different architectures, consistently improving accuracy over ReLU and other activation functions by significant margins. The approach can therefore be used as an automated optimization step in applying deep learning to new tasks.
Evolutionary Optimization of Deep Learning Activation Functions
Garrett Bingham*, William Macke*, and Risto Miikkulainen
GECCO 2020
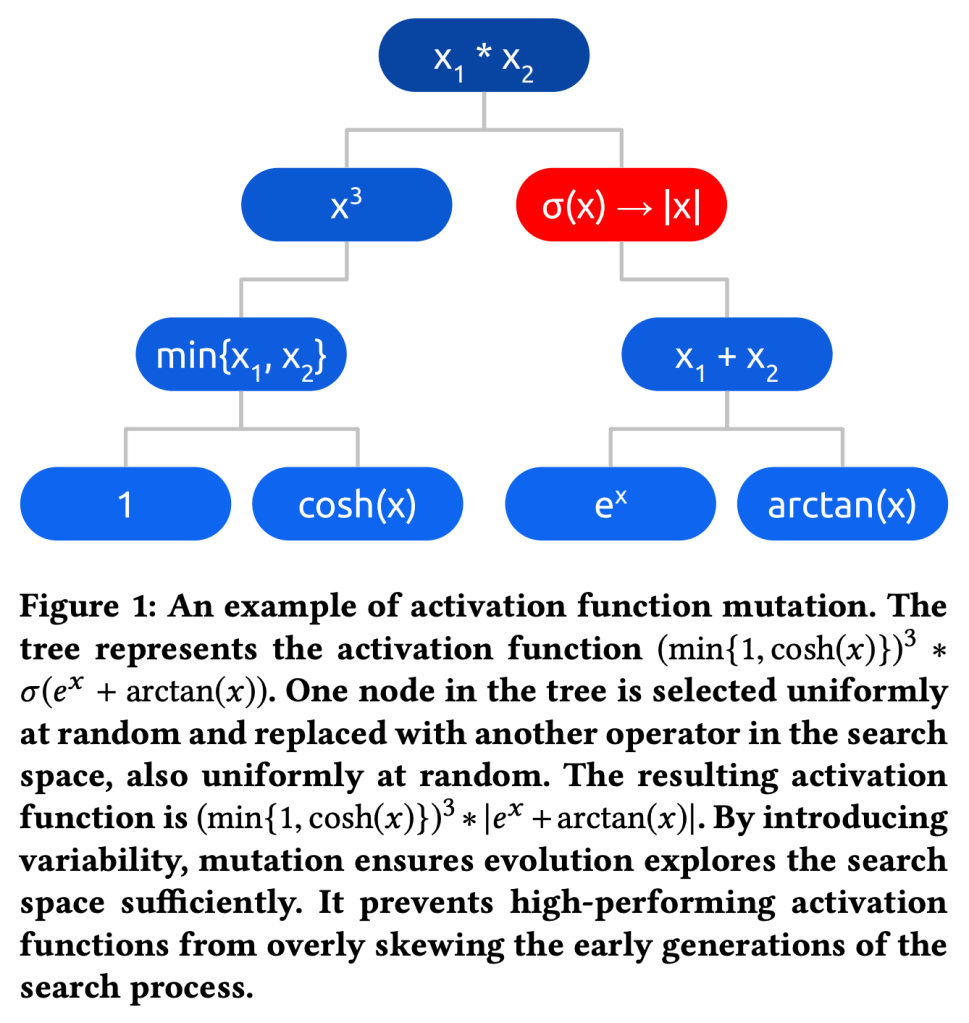
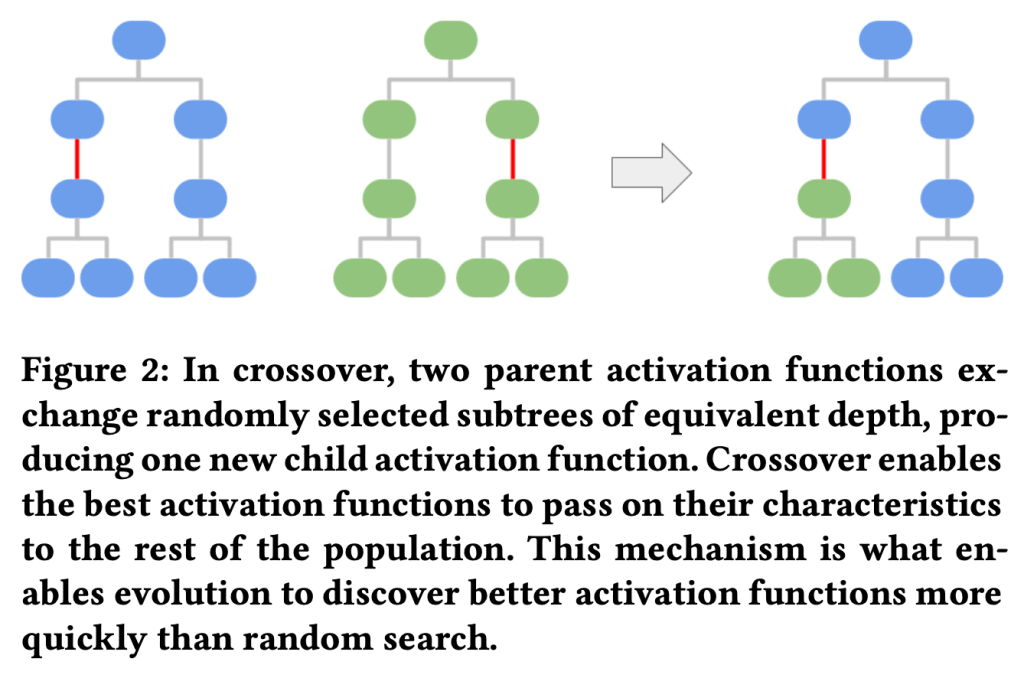
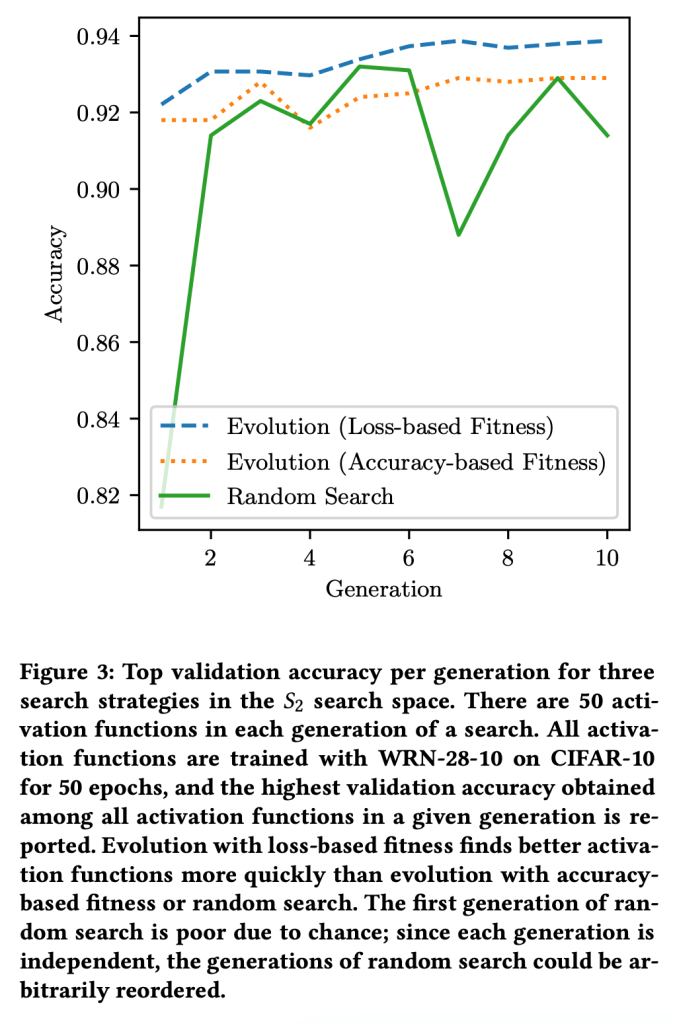
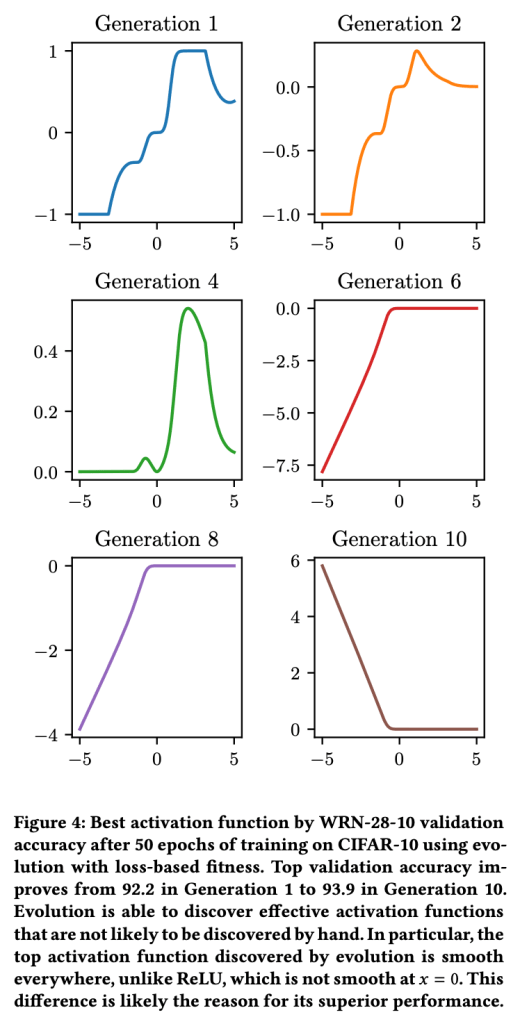
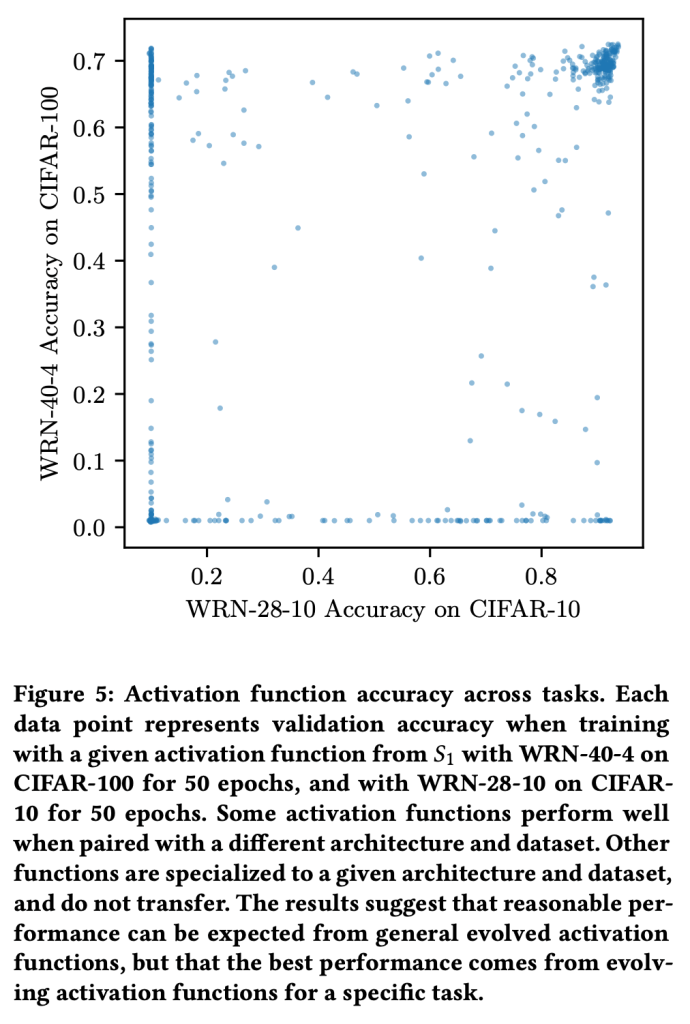
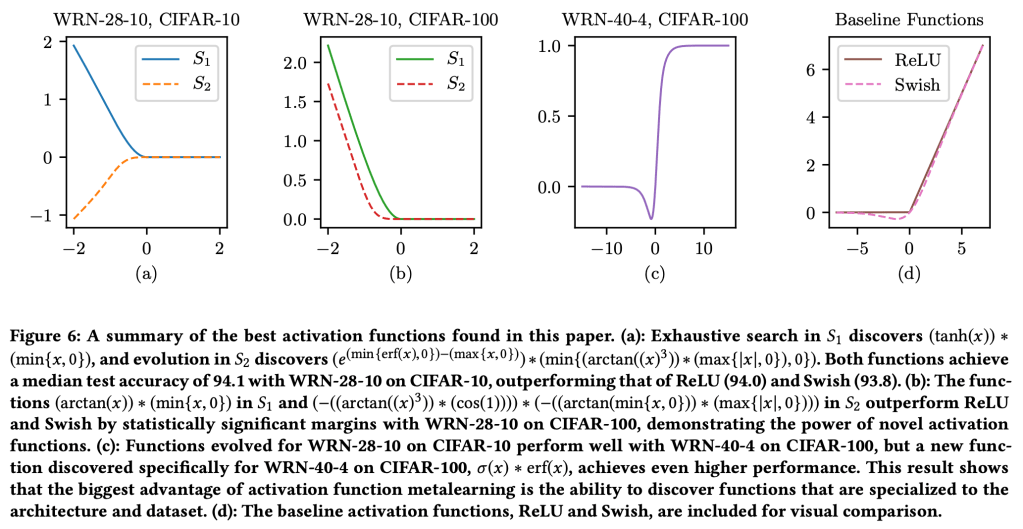



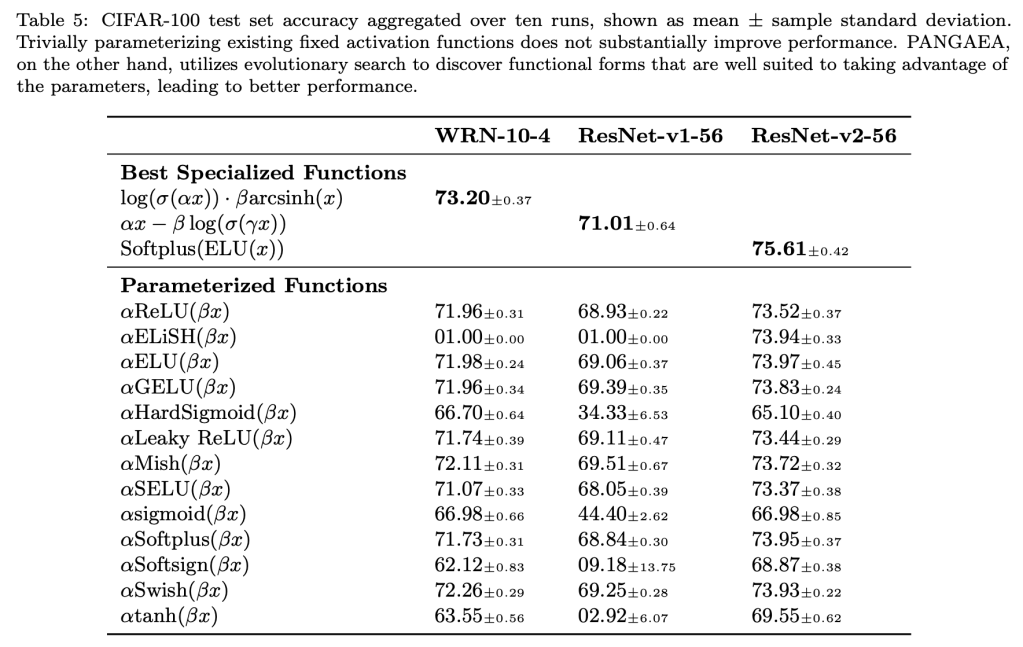
The choice of activation function can have a large effect on the performance of a neural network. While there have been some attempts to hand-engineer novel activation functions, the Rectified Linear Unit (ReLU) remains the most commonly-used in practice. This paper shows that evolutionary algorithms can discover novel activation functions that outperform ReLU. A tree-based search space of candidate activation functions is defined and explored with mutation, crossover, and exhaustive search. Experiments on training wide residual networks on the CIFAR-10 and CIFAR-100 image datasets show that this approach is effective. Replacing ReLU with evolved activation functions results in statistically significant increases in network accuracy. Optimal performance is achieved when evolution is allowed to customize activation functions to a particular task; however, these novel activation functions are shown to generalize, achieving high performance across tasks. Evolutionary optimization of activation functions is therefore a promising new dimension of metalearning in neural networks.
Improving Low-Resource Cross-lingual Document Retrieval by Reranking with Deep Bilingual Representations
Rui Zhang, Caitlin Westerfield, Sungrok Shim, Garrett Bingham, Alexander Fabbri, William Hu, Neha Verma, and Dragomir Radev
ACL 2019
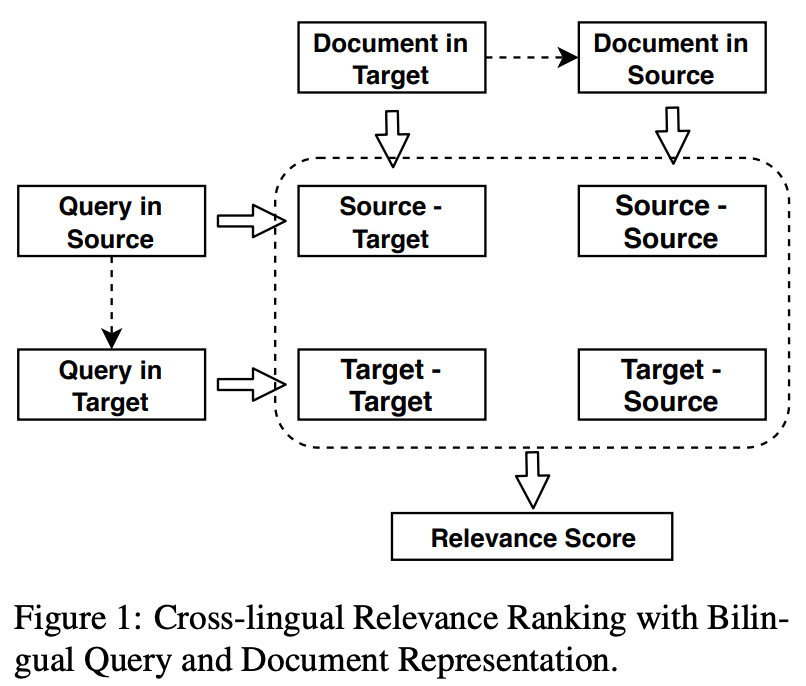
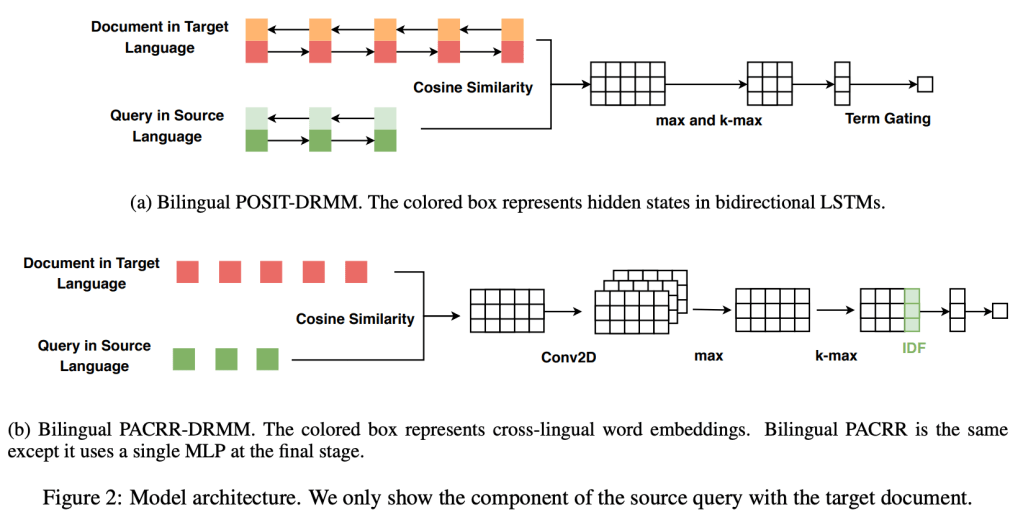
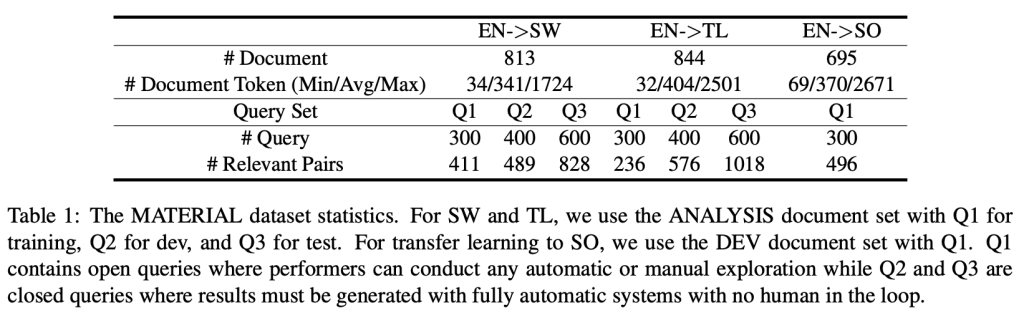

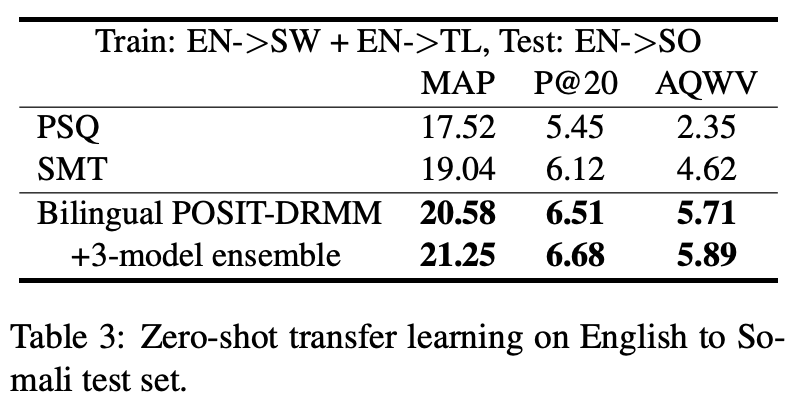
In this paper, we propose to boost low-resource cross-lingual document retrieval performance with deep bilingual query-document representations. We match queries and documents in both source and target languages with four components, each of which is implemented as a term interaction-based deep neural network with cross-lingual word embeddings as input. By including query likelihood scores as extra features, our model effectively learns to rerank the retrieved documents by using a small number of relevance labels for low-resource language pairs. Due to the shared cross-lingual word embedding space, the model can also be directly applied to another language pair without any training label. Experimental results on the Material dataset show that our model outperforms the competitive translation-based baselines on English-Swahili, English-Tagalog, and English-Somali cross-lingual information retrieval tasks.
